Idempotent Data Pipelines
A key property of a fault-tolerant and easy-to-operate data pipeline is idempotence. 1
When an operation is idempotent, it means if we perform it multiple times, the result will be the same as if we ran it once. In math, we express an idempotent function as: .
Consider a simple data pipeline task that loads and transforms source records into batches, then stores the result in a relational database.
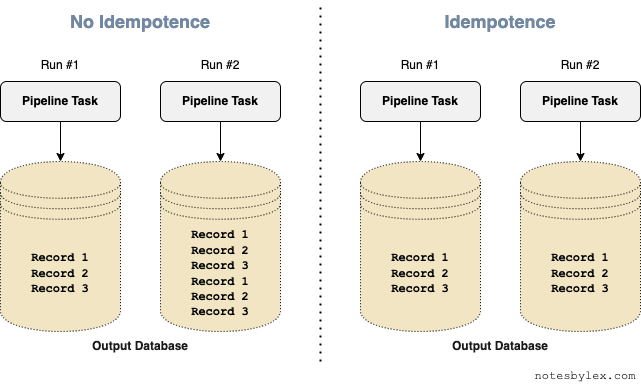
If a pipeline is not idempotent, running the job twice would generate 2x as many records as running it once. Therefore we must take care only to run our job once. If the pipeline fails halfway through, we must ensure that we resume it from where it broke. However, if it failed midway through a batch (especially one that partially succeeded in writing to the database), it may become difficult or near impossible to resume. Our only action is to clear the destination database and run the pipeline from the start or manually correct the destination database by hand.
On the other hand, an idempotent pipeline can be run infinite times and only generates one set of records. With this configuration, we can safely resume from somewhere before the failed batch, in or worst case, restart the entire pipeline from scratch. We could even have pipeline tasks automatically restart on failure.
To achieve idempotence, we must figure out how to uniquely identify our transformed records. Sometimes this is as simple as taking a primary key already provided in the source data. Other times we need to concatenate metadata together to identify a record uniquely. Sometimes the entire body of a source record must be hashed to identify it uniquely.
A side benefit of doing this is that you will have a richer understanding of your source data and transformations. It will force you to think about what makes each record unique and what you consider a duplicate.
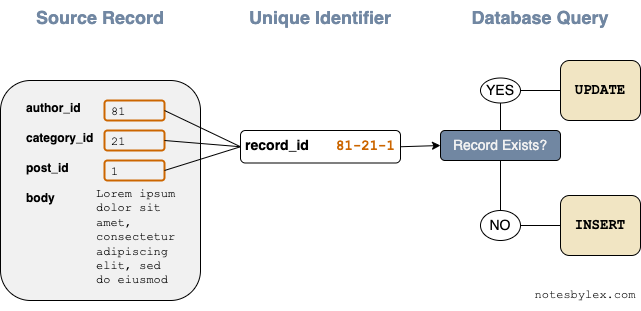
Now our pipeline can use the unique identifier to check if the destination record exists, performing either an update, delete or perform a no-op, depending on what makes sense for our problem. Another advantage of doing it this way means if our transformations need adjustments, we can make them and rerun the pipeline when needed.
Performing a query to check for existing records will add performance overhead to the pipeline; however, the savings in operational complexity far outweigh the penalty in my experience. If you can just rerun parts of your system on errors, or when you find that your transforms need to be updated, you will spend far less time babysitting them.
It's not just pipelines that benefit from idempotence. In a blog post, Eric Lathrop describes a customer billing operation that he makes dramatically easier to operate after introducing idempotence.
It's much easier to build idempotence from the start than bolting it on later.
-
Idempotence is closely related to Declarative programming, a paradigm used amongst Infrastructure As Code practitioners. ↩
-
Inspired by this diagram from Data Pipelines with Apache Airflow. ↩