Neural Codec Language Models are Zero-Shot Text-to-Speech Synthesizers
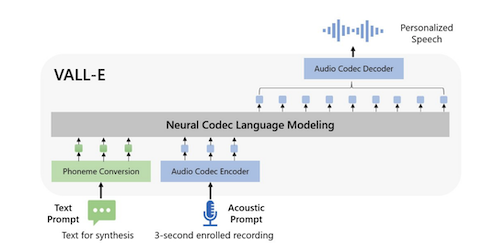
VALL-E can generate speech in anyone's voice with only a 3-second sample of the speaker and some text
VALL-E can generate speech in anyone's voice with only a 3-second sample of the speaker and some text

A tokeniser for audio

An activation function for modelling data with periodicity (repeating patterns)
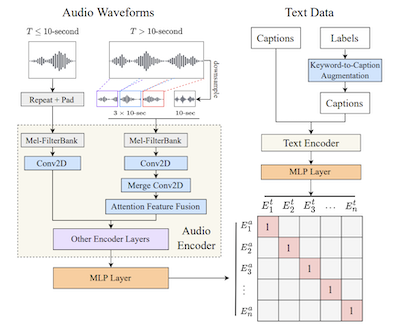
Notes from paper Large-scale Contrastive Language-Audio Pre-training with Feature Fusion and Keyword-to-Caption Augmentation by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov
A sound wave visualisation of frequency over time

A measure of how accurately the source signal was digitally represented

Wave of pressure which our ears can perceive