Decomposing LLM Judge Scores Into Yes/No Questions

An LLM-judge approach that brings interpretability and actionability to your scores.
An LLM-judge approach that brings interpretability and actionability to your scores.
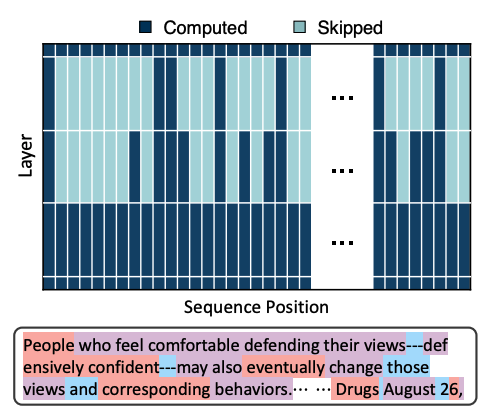
Optimising computation at the token-level
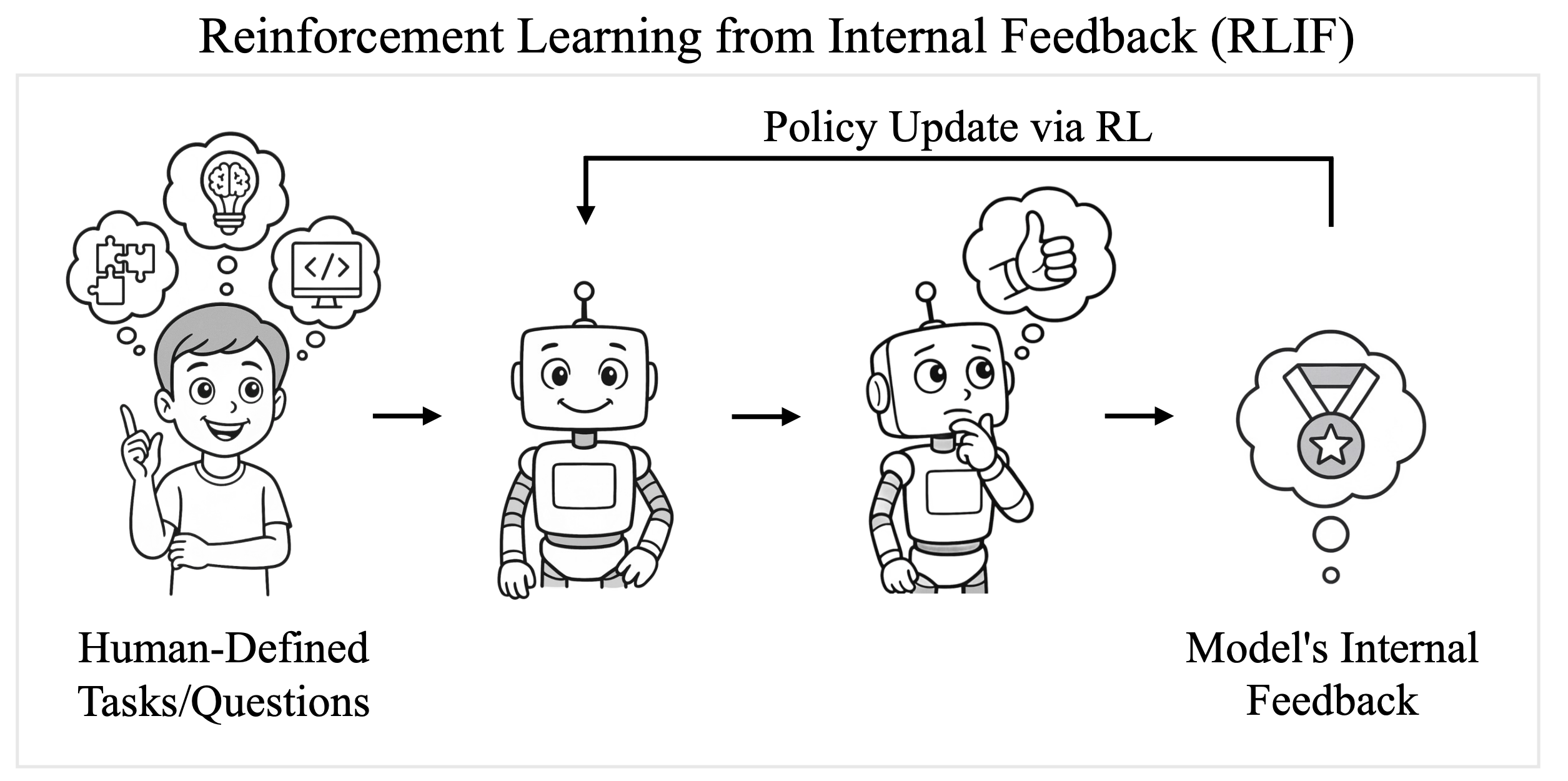
aka Self-Confidence is All You Need
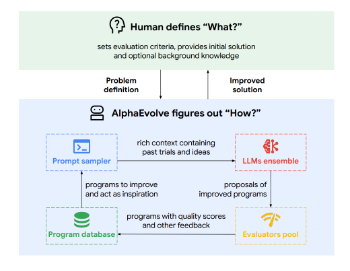
Using evolutionary algorithms with LLM-coding agents

learn to reason without any human-annotated data.
a parameter that controls how confident Softmax predictions are
Routes LLM tasks to cheaper or more powerful models based on task novelty.

improve zero-shot prompt performance of LLMs by adding “Let’s think step by step” before each answer
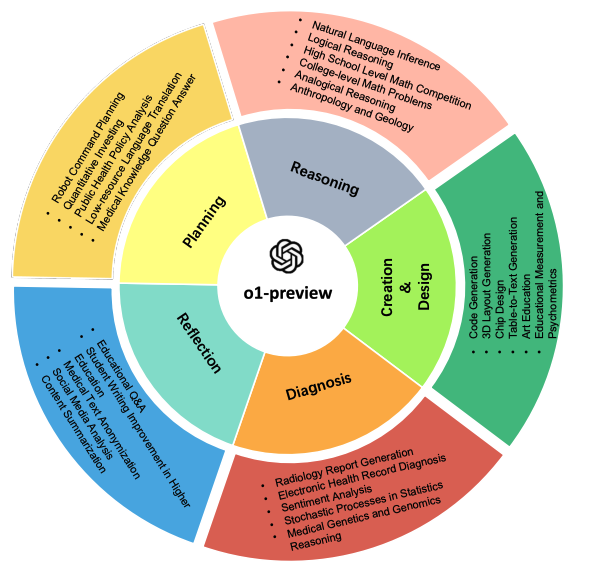
a comprehensive evaluation of o1-preview across many tasks and domains.
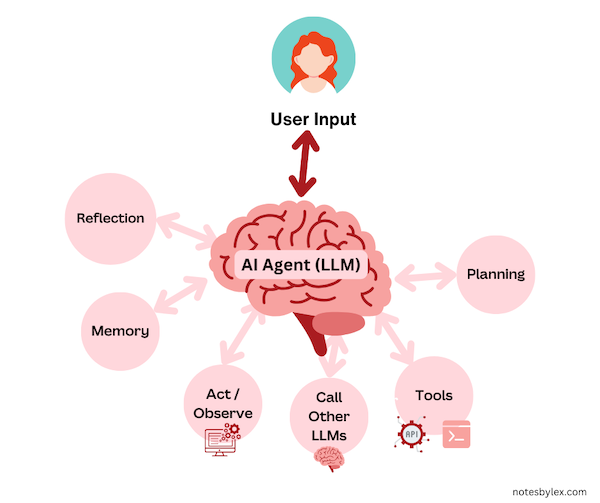
an approach to utilising LLMs that involve multi-state interactions.