Scaled-Dot Product Attention
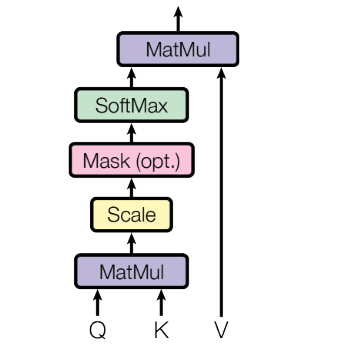
Scaled-Dot Product Attention is the specific formulation of Self-Attention introduced in Attention Is All You Need (Vaswani et al., 2023). It is used in the Transformer architecture and in most subsequent large language models.
The mechanism is identical to standard dot-product self-attention, with one addition: scores are divided by the square root of the attention dimension before the softmax.
Why scale?
As the attention dimension grows, the dot products between query and key vectors tend to grow in magnitude: there are more terms being summed. Large values fed into the softmax push it into regions with very small gradients, making training slow and unstable.
Dividing by keeps the scores in a stable range without changing their relative ordering, since all scores are scaled by the same factor (Vaswani et al., 2023).
scores = query @ key.transpose(2, 1)
scores = scores / math.sqrt(attention_dim) # the "scaled" part
scores = softmax(scores, dim=-1)
out = scores @ value
For a full walkthrough of the self-attention mechanism including input preparation, the QKV projections, masking, and the complete PyTorch module, see Self-Attention.
References
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need. August 2023. arXiv:1706.03762, doi:10.48550/arXiv.1706.03762. ↩ 1 2