Multi-head Attention
A key layer in the Transformer architecture which represents a stack of Scaled-Dot Product Attention attention modules.
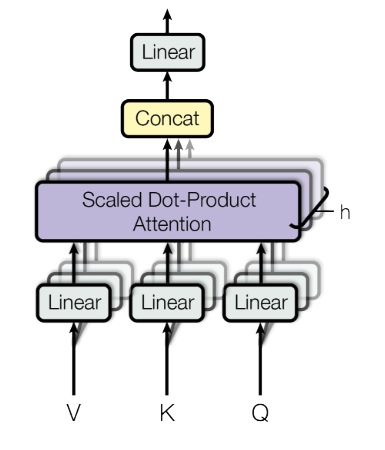
A key layer in the Transformer architecture which represents a stack of Scaled-Dot Product Attention attention modules.