Optimising Computation At The Token-Level
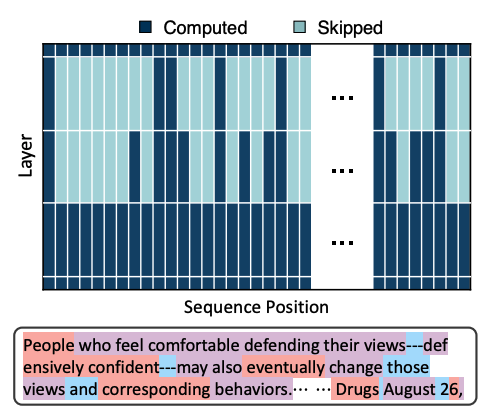
Optimising computation at the token-level
Optimising computation at the token-level
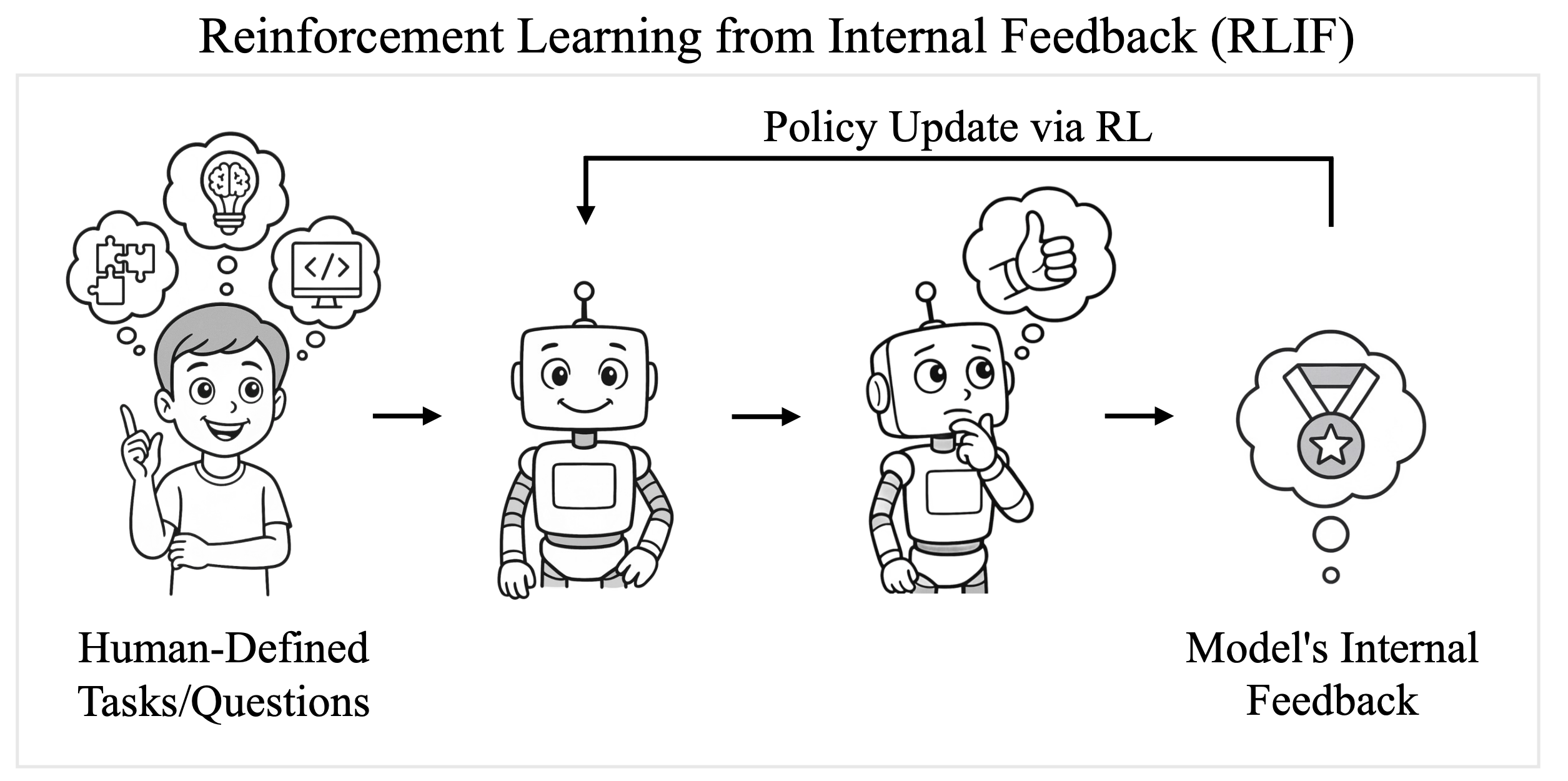
aka Self-Confidence is All You Need

on John Carmack's Upperbound 25 Talk Notes
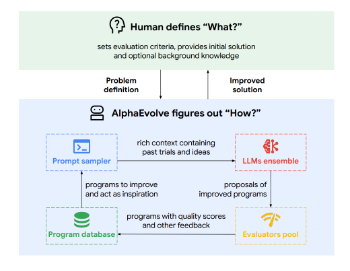
Using evolutionary algorithms with LLM-coding agents
an alternative training method to backprop that does local layer learning

learn to reason without any human-annotated data.
a classic paper applying neural networks to RL for game playing

improve zero-shot prompt performance of LLMs by adding “Let’s think step by step” before each answer
improve the Encoder/Decoder alignment with an Attention Mechanism
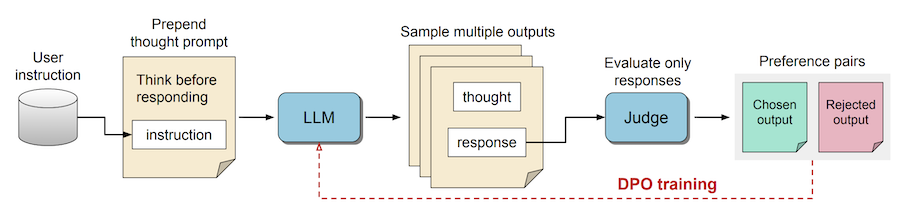
a prompting and fine-tuning method that enables LLMs to engage in a "thinking" process before generating responses