Neural Machine Translation by Jointly Learning to Align and Translate (Sep 2014)
These are my notes from the paper Neural Machine Translation by Jointly Learning to Align and Translate (2014) by Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio.
Overview
This paper proposed an improvement to the RNN Encoder-Decoder 1 network architecture, introducing an "attention mechanism" to the decoder, which significantly improved performance over longer sentences. The concept of attention went on to become extremely influential in Machine Learning.
At the time, neural networks had emerged as a promising approach to machine translation, where researchers were aiming for an end-to-end translation model, in contrast to the state-of-the-art statistical phrase-based translation methods, which involved many individually trained components. The RNN Encoder-Decoder approach would encode an input sentence into a fixed-length context vector; a decoder would then output a translation using the context vector. The encoder and decoder are jointly trained on a dataset of text pairs, where the goal is to maximise the probability of the target given the input.
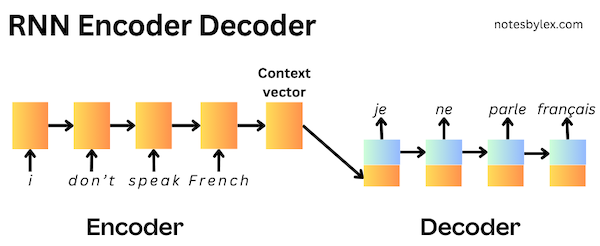
However, this approach struggles with longer sentences, as the encoder has to drop information to compress it into a fixed-length context vector.
The authors proposed modifying the encoder to output a sequence with one hidden representation per input word, then adding a search mechanism to the decoder, allowing it to find the most relevant information in the input sequence to predict each word in the output sequence.
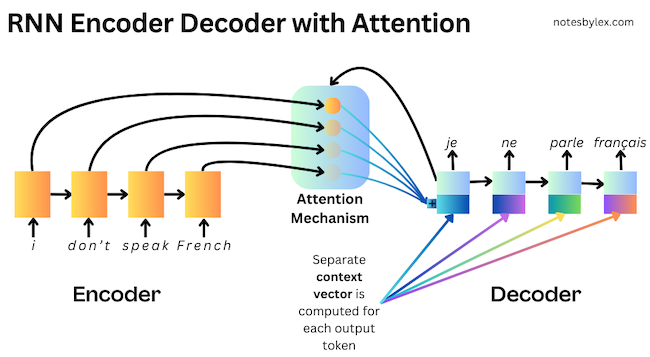
They likened the modification to the human notion of "attention", calling it an Attention Mechanism. Though not the first Machine Learning paper to propose applying human-like attention to model architectures 2, this approach was very influential in NLP, leading to a lot of research eventually converging on an entirely attention-based architecture called the Transformer.
Architecture Details
The authors propose an RNNSearch model: an Encoder / Decoder model with an attention mechanism. For comparison, they train RNNencdec, which follows the standard RNN Encoder / Decoder architecture 2 with the encoder returning a fixed-length context vector.
To demonstrate the ability to handle longer sequences, they train each model twice:
- First, with sentences of length up to 30 words:
RNNencdec-30,RNNsearch-30 - Next, with sentences of size up to 50 words:
RNNencdec-50,RNNsearch-50
Encoder
For the RNN, they use a Bidirectional RNN: a Gated Recurrent Unit (GRU).
Each input token is fed into an embedding layer, , and then a GRU encodes into a forward and backward "annotation" per token, concatenated to make a single representation, .
The idea is to allow each annotation to summarise the preceding and the following words, providing the most possible representation for the attention mechanism.
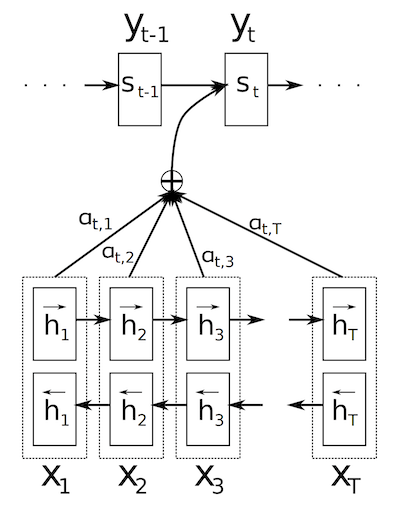
Figure 1: The graphical illustration of the proposed model trying to generate the t-th target word given a source sentence ( )
Decoder
For the decoder, they use a uni-directional Gated Recurrent Unit.
The initial hidden state is computed as an initialisation layer, which comprises a linear layer followed by a tanh activation function.
where .
For each prediction step, they calculate the word probability as:
Where
- is the embedding of the token from the previous step.
- is the hidden state output from the previous layer.
- is the context vector.
The context vector, is calculated at each step as follows:
The weights, , are calculated by the alignment (Attention) model.
Alignment Model (Attention)
The alignment scores are calculated by combining a projection of the decoder's previous state and a projection of the encoder output, then applying tanh activation followed by a linear combination with another weight vector.
This function gives us an output score for each token in the input sequence. Finally, we can perform a Softmax calculation to convert the weights to probability distribution:
Maxout
The final layer, which returns the probabilities for each word, uses a Maxout layer to generate the final probabilities. A Maxout layer acts as a form of regularisation. It projects the input vector onto multiple "buckets" and selects the maximum value from each bucket. This process introduces non-linearity and helps prevent overfitting, akin to dropout.
Training Params
- Algorithm: Stochasic Gradient Descent (SGD)
- Optimiser: Adadelta (Zeiler, 2012)
- Batch Size: 80 sentences
- Training Duration: Approximately 5 days per model
- Inference method: Beam search
- Task: English-to-French translation
- Dataset: bilingual, parallel corpora provided by ACL WMT 14.
- Word count: 850 (reduced to 348M)
- Components:
- Europarl (61M words)
- News Commentary (5.5M)
- UN (421M)
- two crawled corpora of 90M and 272.5M words, respectively
- Metric: BLEU Score.
- Tokeniser: from open-source machine translation package Moses. They shortlist the most frequent 30k words and map everything else to
[UNK]. - Comparisons: They compare RNNsearch with a standard RNN Encoder-Decoder, RNNenc and Moses, the state-of-the-art translation package.
- Test Set: For the test set, they evaluate
news-test-2014from WMT'14, which contains 3003 sentences not in training - Valid Set: They concat
news-test-2012andnews-test-2013. - Initialisation: Orthogonal for recurrent weights, Gaussian ($0, 0.01^2$) for feed-forward weights, zeros for biases.
Results
They record results on all test data with only examples that don't contain unknown tokens.
The RNNsearch-50 model achieved a BLEU score of 34.16 on sentences with unknown tokens excluded, significantly outperforming the RNNencdec-50 model, which scored 26.71 and training RNNsearch-50 to convergence beat the state-of-the-art Moses. However, when unknown tokens are included, the model performs considerably worse.
RNNsearch was much better at longer sentences than RNNenc.
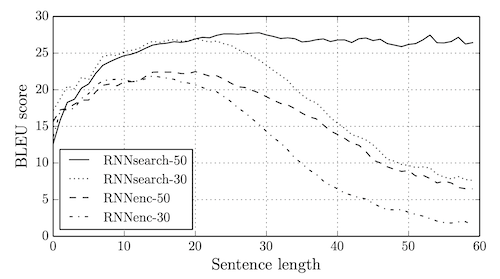
Figure 2: The BLEU scores of the generated translations on the test set with respect to the lengths of the sentences.
| Model | All | No UNK |
|---|---|---|
| RNNencdec-30 | 13.93 | 24.19 |
| RNNsearch-30 | 21.50 | 31.44 |
| RNNencdec-50 | 17.82 | 26.71 |
| RNNsearch-50 | 26.75 | 34.16 |
| RNNsearch-50* | 28.45 | 36.15 |
| Moses | 33.30 | 35.63 |
*Note: RNNsearch-50* was trained much longer until the performance on the development set stopped improving.
Interpreting Attention
One benefit of calculating attention weights for each output word is that they are interpretable, allowing us to visualise word alignments.
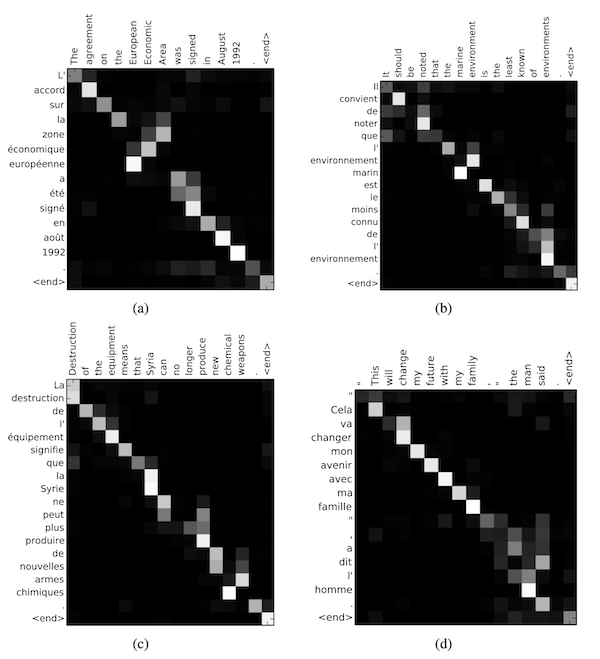
Figure 3. Four sample alignments that were found by RNNsearch-50.
As we can see, typically, words are aligned to similarly positioned words in a sentence, but not always.
-
Cho, K., van Merrienboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv. https://arxiv.org/abs/1406.1078 ↩
-
Brauwers, G., & Frasincar, F. (2023). A general survey on attention mechanisms in deep learning. IEEE Transactions on Knowledge and Data Engineering, 35(4), 3279–3298. https://doi.org/10.1109/tkde.2021.3126456 ↩↩