Week 5 - What are eigenvalues and eigenvectors?
What are eigen-things?
What are eigenvalues and eigenvectors?
- "Eigen" is translated from German as "characteristic."
- "Eigenproblem" is about finding characteristic properties of something.
-
Geometric interpretation of Eigenvector and Eigenvalue (00:45-04:22)
-
Though we typically visualize linear transformations based on how they affect a single vector, we can also consider how they affect every vector in the space by drawing a square.
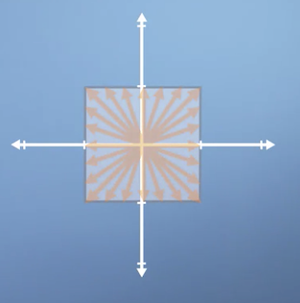
We can then see how a transformation distorts the shape of the square.
-
If we apply a scaling of 2 in vertical direction the square becomes a rectangle.
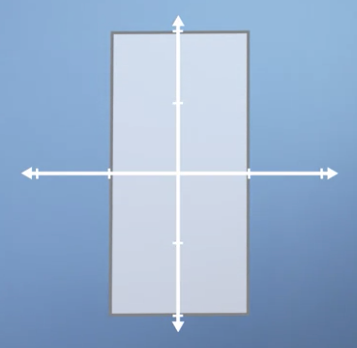
-
A horizontal sheer on the other hand looks like this:

-
When we perform these operations:
- Some vectors point in the same direction but change length.
- Some vectors point in a new direction.
- Some vectors do not change.
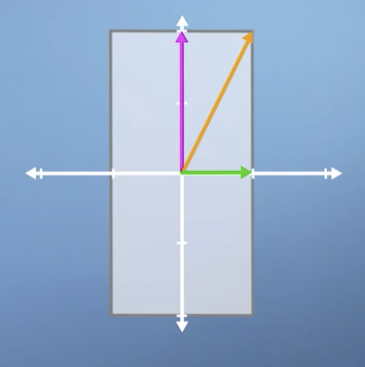
-
The vectors that point in the same direction we refer to as Eigenvector.
- The vectors that point in the same direction and whose size does not change are said to have Eigenvalues 1.
- In the above example, the vertical Eigenvector doubles in length, with an Eigenvalue of 2.
- In a pure sheer operation, only the horizontal vector is unchanged. So the transformation has 1 Eigenvector.
- In a rotation, there are no Eigenvectors.
-
Getting into the detail of eigenproblems
Special eigen-cases
- Recap (00:00-00:18):
- Eigenvector lie along the same span before and after applying a linear transform to a space.
- Eigenvalues are the amount we stretch each of those vectors in the process.
-
3 special Eigen-cases (00:18-02:15)
- Uniform scaling
- Scale by the same amount in each direction.
- All vectors are Eigenvectors.
-
180° rotation
- In regular rotation, there are no Eigenvectors. However, in 180° rotation, all vectors become Eigenvector pointing in the opposite direction.
-
Since they are pointing in the opposite direction, we say they have Eigenvalues of -1.
-
- In regular rotation, there are no Eigenvectors. However, in 180° rotation, all vectors become Eigenvector pointing in the opposite direction.
-
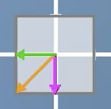
Combination of horizontal sheer and vertical scaling
-
Has 2 Eigenvector. The horizontal vector and a 2nd Eigenvector between the orange and pink vector.
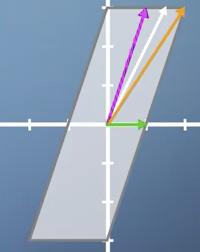
-
- Uniform scaling
-
We can calculate Eigenvalues in much higher dimensions.
-
In the 3d example, finding the Eigenvector also tells you the axis of rotation.
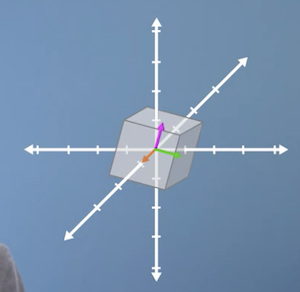
-
Calculating eigenvectors
- Calculating Eigenvector in general case (00:24-04:36)
- Given transformation , Eigenvectors stay on the same span after the transformation.
- We can write the expression as where is a scalar value, and is the Eigenvector.
- Trying to find values of x that make the two sides equal.
- Having A applied to them scales their length (or nothing, same as scaling by 1)
- A is an n-dimensional transform.
- To find the solution of the express, we can rewrite:
- The is an Identity Matrix that allows us to subtract a matrix by a scalar, which would otherwise not be defined.
- For the left-hand side to be 0, either:
- Contents of the bracket are 0.
- x is 0
- We are not interested in the 2nd case as it means it has no length or direction. We call it a "trivial solution."
- We can test if a matrix operation results in 0 output by calculating its Matrix Determinate:
- We can apply it to an arbitrary 2x2 matrix: as follows:
- Evaluating that gives us the Characteristic Polynomial:
- Our Eigenvalues are the solution to this equation. We can then plug the solutions into the original expression.
- Applying to a simple vertical scaling transformation (04:36-07:53):
- Give vertical scaling matrix:
- We calculate the determinate of : as which equals
- This means our equation has solutions at and .
- We can sub these two values back in:
- 1st case: :
- 2nd case: :
- We know that any vectors that point along the horizontal axis can be Eigenvector of this system.
- :
- When , the Eigenvector can point anywhere along the horizontal axis.
- :
- When , the Eigenvector can point anywhere along the vertical axis.
- :
- Applying to a 90° rotation transformation (07:54-)
- Transformation:
- Applying the formula gives us
- Which means there are no Eigenvectors.
- Note that we could still calculate imaginary Eigenvectors using imaginary numbers.
- In practice, you never have to calculate Eigenvectors by hand.
When changing to the eigenbasis is useful
Changing to the eigenbasis
-
Multiple matrix multiplications
- Combines the idea of finding Eigenvector and changing basis.
-
Motivation:
- Sometimes, we have to apply the same matrix multiplication many times.
- For example, if you have a matrix that represents a change to a single particle after a specific timestep: and you apply to a matrix you end up with result:
-
You can apply it again to that result
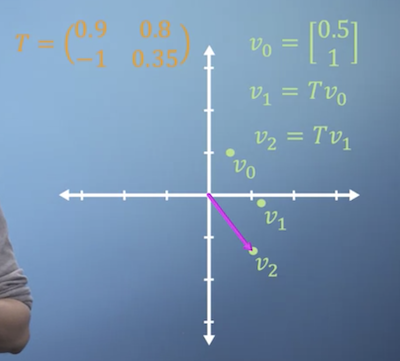
-
If you wanted to apply it millions of times, the operation could be expensive.
- Can instead square to get the same result: or to the power of any :
- If T was is a Diagonal Matrices, where all terms along the leading diagonal are 0, you can simply square the non-zero values as:
- When all terms except those along diagonal are 0.
- If the matrix isn't diagonal, you can construct a Diagonal Matrix using Eigenanalysis.
- Constructing a Diagonal Matrix
- Plug in Eigenvectors as columns:
- Create a diagonal matrix from that:
- We then want to convert back to the original transformation, which we can use the inverse.
- In summary:
- Then would be:
- Since returns the identity, we can rewrite as:
- The whole process looks like this:
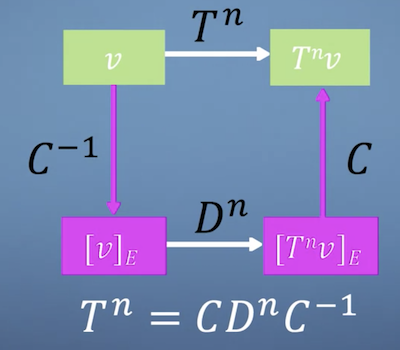
Eigenbasis example
- Give a transformation matrix:
- When we multiply it with vector the vector is unchanged, so it's an Eigenvector with Eigenvalue 1.
- When multiplying with gives us , so it's an Eigenvector with Eigenvalue 2.
- So, the Eigenvectors are:
- :
- :
- Transformation using squaring:
- What happens to vector when you multiply it numerous times?
- If we instead started with : we can get straight to the answer:
- Transformation using Eigenbasis approach:
- We have our conversion matrix from our Eigenvectors:
- We know the inverse is:
- We can take the Eigenvalues to construct the diagonal matrix is
- The problem is constructed as:
- If we apply that to our original vector, we get the same results:
Making the PageRank algorithm
Introduction to PageRank
- PageRank (00:00-07:20)
- Ranks websites by importance based on the importance of pages that link to them.
- Central assumption: "the importance of a website is related it links to and from other websites."
-
Model represents a model mini internet:
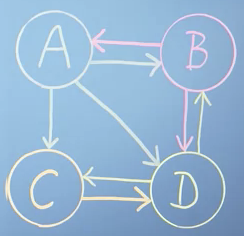
- Network would have vector: where a represents a link to it.
- We then normalise the vector so the total probabilty sums to 1:
- Network would have vector:
- Nework :
- Network :
- We can then convert each vector into a column of a matrix :
- This matrix represents the probability of getting to each page. I.e., the only way to get to is from .
- You then need to know the probability of getting to . You would need to be at either or .
- The problem is "self-referential": the ranks of all the pages depend on the ranks of others.
- The columns are for external links, and the rows describe inward links normalized from the origin page.
- An expression can be written using vector to store the rank of all web pages.
- We can then get the rank for webpage A, as follows:
- That means that the rank of is the sum of ranks of all pages that link to it, weighted by specific link probability taken from .
- We can rewrite that as simple matrix multiplication for all web pages:
- Since we start out not knowning , we assume all ranks are equal and normalise by total webpages:
- Then we keep updating iterative until stops changing:
- Applying repeated means, we are solving iteratively until stops changing.
- This means that is an Eigenvector of matrix , with an Eigenvalue of 1.
- We might assume that we could apply the Diagonalisation method, but we would first need to know all the Eigenvalues, which is what we're trying to find.
- Though there are many approaches for efficiently calculating Eigenvectors, randomly multiplying a randomly selected initial guest vector by a matrix, called the Power Method, is still very effective.
- The power method will only give you one Eigenvector for an n by n webpage system, the vector you get will be the one you're looking for with an Eigenvalue of 1.
- The graph for the whole internet will be very Sparse Matrix. Algorithms exist that allow us to perform efficient matrix multiplication.
- The damping factor (07:20-08:24)
- Adds an additional term to formula:
- It's the probability that a random web surfer will type a URL instead of clicking
- Finds compromise between speed and stability.
- Ranks websites by importance based on the importance of pages that link to them.