RDF
RDF (or Resource Description Framework) is a data model for representing data as a graph. RDF is the foundational technology for the Semantic Web, which was Tim Berners-Lee's vision for a machine-readable web, once described as Web 3.0 (unrelated to the crypto bros blockchain-powered Web3). RDF is also the backbone of a standard for interconnecting datasets called Linked Data.
Though the Semantic Web never fully materialised, partially due to its reliance on users to input correct data 1, the RDF standard does live on in multiple forms. Many social media sites and feed readers also support various RDF serialisation standards, such as JSON-LD, to read metadata on websites 4. I've also seen it deployed in organisations for taxonomy management, such as maintaining databases of keywords and their relationships (e.g., if an item is a Daffodil, it's also a Flower, which means it's also a Plant).
It's worth taking the time to wrap your head around RDF, although it can seem a little cumbersome at first.
In RDF, data points are defined as triples in the form: <subject> <predicate> <object>.
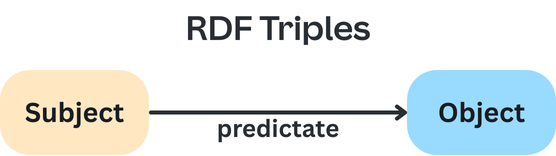
Jumping straight into an example, here's how I might represent information about myself in this form:
<Lex> <is a> <person>
<Lex> <has occupation> <Software Engineer>
<Lex> <has pet> <Doggo>
Then let's also define some triples for my dog, Doggo:
<Doggo> <is a> <dog>
<Doggo> <has breed> <Staghound>
<Doggo> <is aged> 6
A key detail of RDF is that Subjects and Predicates must be represented as an IRI (Internationalised Resource Identifier), of which URLs are a subset. Objects can be IRIs, but can also be literals: strings, numbers, dates, etc.
These IRIs serve as globally unique identifiers for resources (the "R" in RDF). For instance, I could describe myself using my website's URL and reference schema.org's standardised definition of a person, so that other people would know I was a person.
<https://notesbylex.com/Lex> <rdf:type> <http://schema.org/Person>
This IRI-based approach provides two powerful capabilities. First, it enables shared vocabularies across the internet: different datasets can reference the same definitions, ensuring everyone means the same thing by "Person" or "owns." Second, it allows easy creation of new vocabularies, whether public standards or private organisational schemas.
RDF's graph structure also enables logical reasoning across the data.
For example, given the information:
<Aspirin> <inhibits> <COX-2 enzyme>
<COX-2 enzyme> <produces> <Prostaglandins>
<Prostaglandins> <mediate> <Inflammation>
We can infer that:
<Aspirin> <reduces> <Inflammation>
The technique of representing information in a way that allows us to perform logical inference over it originates from a branch of AI known as Knowledge Representation.
RDF Serialisation
There are multiple ways to serialise RDF data, each with different advantages:
N-Triples
The simplest serialisation format, expressing each triple on a separate line using full URIs. While it is verbose, it's also easy to parse and process programmatically.
The example earlier was an of how I might express myself using N-Triples format:
<https://example.org/person#lex> <https://example.org/hasName> "Lex" .
<https://example.org/person#lex> <https://example.org/hasOccupation> "software engineer" .
<https://example.org/person#lex> <https://example.org/hasPet> <https://example.org/dog#Doggo> .
<https://example.org/dog#Doggo> <https://example.org/hasName> "Doggo" .
<https://example.org/dog#Doggo> <https://example.org/hasBreed> "Staghound" .
<https://example.org/dog#Doggo> <https://example.org/hasAge> 6 .
You'll notice that I've used http://example.org as the prefix for my subjects and predicates. Since RDF mandates the use of URIs for these attributes, http://example.org is a reserved domain name specifically designated for use in documentation and examples (see RFC 2606).
Turtle (Terse RDF Triple Language)
Turtle (or Terse RDF Triple Language) is a human-readable RDF serialisation format. It includes features like:
- Prefixes to reduce redundant URL prefixes.
- A semicolon (
;) to keep the same subject, continues with a new predicate - A comma (
,) keeps the same subject and predicate, adds a new object. "a"shortcut - replaces "is of type".- Language tags to specify labels in different languages.
Example:
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix ex: <https://example.org/> .
ex:person#lex
a foaf:Person ;
foaf:name "Lex" ;
ex:hasOccupation "software engineer" ;
ex:hasPet ex:dog#Doggo .
ex:dog#Doggo
a ex:Dog ;
foaf:name "Doggo" ;
ex:hasBreed "Staghound" ;
ex:hasAge 6 .
Turtle is one of the most common RDF serialisation approaches, and most RDF databases tend to support it.
RDFa
RDFa allows RDF data to be embedded directly into HTML markup using special attributes, which enables web pages to contain machine-readable structured data alongside human-readable content. RDFa is useful for search engine optimisation and semantic web apps.
RDFa attributes:
about- specifies the subject of the RDF statements.property- creates a literal value relationship.rel- create a resource relationship.resource- specifies the object resource.typeof- declares the RDF type of the subject.datatype- specifies the data type of literal values.
Example:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:ex="https://example.org/">
<head>
<title>Person and Pet Profile</title>
</head>
<body>
<div about="https://example.org/person#lex" typeof="foaf:Person">
<h1 property="foaf:name">Lex</h1>
<p>Occupation: <span property="ex:hasOccupation">software engineer</span></p>
<p>Pet ownership:</p>
<div about="https://example.org/dog#Doggo" typeof="ex:Dog" rel="ex:hasPet">
<h2 property="foaf:name">Doggo</h2>
<p>Breed: <span property="ex:hasBreed">Staghound</span></p>
<p>Age: <span property="ex:hasAge" datatype="xsd:integer">6</span> years old</p>
</div>
</div>
</body>
</html>
JSON-LD
JSON-LD expresses RDF using familiar JSON syntax while maintaining full RDF compatibility. A good format for working with web applications since it uses common JSON syntax while maintaining full RDF compatibility. Search engines actively use JSON-LD for processing Schema.org structured data.
Keywords of JSON-LD:
@context- defines namespace prefixes and mappings.@id- specifies the subject URI.@type- declares the RDF type.@valueand@type- for typed literal values.@graph- contains an array of linked data objects.
{
"@context": {
"foaf": "http://xmlns.com/foaf/0.1/",
"ex": "https://example.org/",
"xsd": "http://www.w3.org/2001/XMLSchema#"
},
"@graph": [
{
"@id": "ex:person#lex",
"@type": "foaf:Person",
"foaf:name": "Lex",
"ex:hasOccupation": "software engineer",
"ex:hasPet": {
"@id": "ex:dog#Doggo"
}
},
{
"@id": "ex:dog#Doggo",
"@type": "ex:Dog",
"foaf:name": "Doggo",
"ex:hasBreed": "Staghound",
"ex:hasAge": {
"@value": 6,
"@type": "xsd:integer"
}
}
]
}
RDF/XML
One of the first approaches to RDF serialisation, using XML syntax, makes it more verbose but useful for systems already processing XML, but mostly considered less readable than Turtle or JSON-LD formats.
rdf:aboutspecifies the subject URIrdf:resourcecreates relationships to other resourcesrdf:datatypespecifies data types for literal values- Nested elements represent predicates and objects
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:ex="https://example.org/">
<foaf:Person rdf:about="https://example.org/person#lex">
<foaf:name>Lex</foaf:name>
<ex:hasOccupation>software engineer</ex:hasOccupation>
<ex:hasPet rdf:resource="https://example.org/dog#Doggo"/>
</foaf:Person>
<ex:Dog rdf:about="https://example.org/dog#Doggo">
<foaf:name>Doggo</foaf:name>
<ex:hasBreed>Staghound</ex:hasBreed>
<ex:hasAge rdf:datatype="http://www.w3.org/2001/XMLSchema#integer">6</ex:hasAge>
</ex:Dog>
</rdf:RDF>
Blank Nodes
RDF also supports blank nodes (or anonymous nodes) for representing resources without URIs. These are useful when you need to describe something but don't need to give it a permanent identifier. For example, representing an address without creating a URI for it:
ex:person#lex ex:hasAddress [
a ex:Address ;
ex:street "123 Main St" ;
ex:city "Springfield" ;
ex:zipCode "12345"
] .
RDF Vocabulary
RDF provides the structural foundation, but vocabularies define the actual meaning of the data. The RDF ecosystem includes several foundational vocabularies and extensions:
Core RDF Vocabularies
- RDF - The core Resource Description Framework vocabulary that provides basic terms like
rdf:type,rdf:Property, andrdf:Statementfor describing the fundamental structure of RDF data. - RDF Schema - Extends RDF with terms for defining classes (
rdfs:Class), properties (rdfs:Property), subclass relationships (rdfs:subClassOf), and domain/range constraints (rdfs:domain,rdfs:range). - Web Ontology Language (OWL) - A more expressive vocabulary built on RDF and RDFS that adds complex logical constructs like
owl:equivalentClass,owl:disjointWith, andowl:inverseOffor creating sophisticated ontologies and enabling automated reasoning.
Common Application Vocabularies
- FOAF (Friend of a Friend) - for describing people and relationships.
- Dublin Core - for metadata about resources.
- Schema.org - for structured data on web pages.
Ecosystem
While RDF provides the data model, several extensions provide additional capabilities.
- Web Ontology Language (OWL) - A more expressive language built on RDF for creating complex ontologies and reasoning.
- Triplestores - Specialised databases designed to store and efficiently query RDF triple data.
- SPARQL - the standard query language for retrieving and manipulating RDF data, similar to SQL for relational databases.
-
(2018, May 27). Whatever happened to the semantic web? Two-Bit History. https://twobithistory.org/2018/05/27/semantic-web.html ↩
-
Webber, J. (n.d.). RDF vs. property graphs: Choosing the right approach for implementing a knowledge graph. Neo4j. https://neo4j.com/blog/knowledge-graph/rdf-vs-property-graphs-knowledge-graphs/ ↩
-
King, R. D., Rowland, J., Oliver, S. G., Young, M., Aubrey, W., Byrne, E., ... & Sparkes, A. (2009). The automation of science. Science, 324(5923), 85-89. ↩
-
Paterson, C. (2024, August 20). Being on the semantic web is easy, and, frankly, well worth the bother. csvbase. https://csvbase.com/blog/13 ↩