Week 4 - Special applications: Face recognition & Neural style transfer
Face Recognition
What is face recognition
- Face verification
- Input image, name/ID
- Output whether the input image is the actual person.
- Difficult because need to solve a "one shot learning" problem.
- Face recognition
- Has a database of K people.
- Take input image
- Output ID if you find person in database.
- Much harder than verification.
One Shot Learning
- Recognising people using just one example of that person.
- One (bad) approach: create a CNN with a Softmax output with number of outputs equal to number of people in your database.
- Problem: requires retraining everytime you add another person. Also, not very robust.
- Solution: learn a "similarity" function.
- Similarity function:
d(img1, img2) = degree of difference between images- Recognition time, do something like:
if d(img1, img2) <= threshold: return "same"for each image in your database.
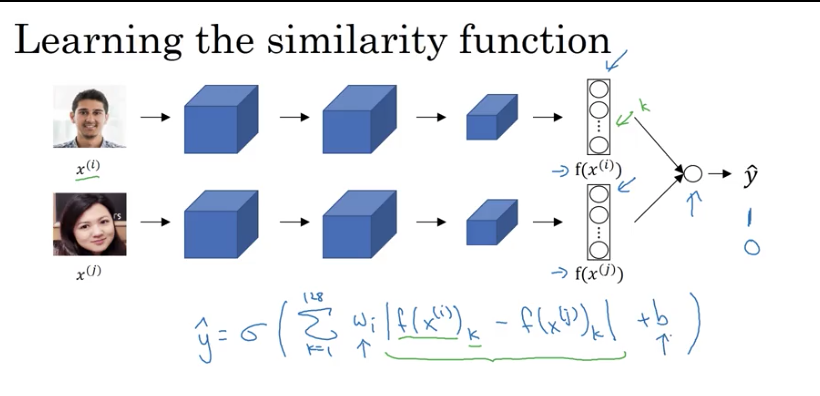
Siamese Network
-
A good way to learn similarity function
D().- Instead of creating a standard CNN with conv layers, FC layers and a softmax, remove the final softmax layer and output a vector of 128 numbers.
- Then, for another image, get another vector of 128 numbers.
- Difference between the images is the norm of the difference:
* Learn parameters so that: if person 1 and person 2 are the same, different should be small and vice versa.
Triplet loss
- Take two pairs of images, one an anchor image (A) and a positive image (a positive example of the same person) (P), then an anchor image a negative example (N).
- Want:
- Can rewrite as:
- Since a trivial solution to the problem is to just set all values to 0, giving you
0 - 0 <= 0, you can subtract an alpha param from 0, giving you: or - Refer to the param as the "margin" param.
- Loss function is defined for triplets of images:
- The max function ensures the loss always aims to be below 0.
- Loss for the entire set is:
- Need a training set with multiple images of the same person.
- If you choose A,P,N at random, the constraint should be easy to satisfy. Therefore, want to choose A,P,N that are hard to train on (maybe choose similar images that aren't the same person).
- Commercial face recognition systems are generally trained on very large sets (1M+).
Face Verification and Binary Classification
-
An alternate to triplet loss could be to construct two conv NN that are merged into a single binary output layer that predicts whether they're a match or not.
Neural Style Transfer
What is neural style transfer?
- Given two images, try to generate a new picture with the content of the first and the style of the second.
- Going to represent the content image as C, the style as S and the generated as G.
What are deep ConvNets learning?
- From paper Visualising and Understand Convolutional Neural Networks.
- Visualising what a deep network is learning:
- Pick a hidden unit in layer 1, go through your training set find image patches that maximise a unit's activation.
- Do it for other units.
- Can then visualise other layers:
- Layer 1: textures.
- Layer 2: more complex textures.
- Layer 3 and 4: features (dogs, water).

- Layer 5: even more sophisticated things.

Cost function
- From A neural algorithm of artistic style.
-
Neural style transfer cost function:
-
Add two hyper params for weight of content and style:
-
Initialise the generated image G randomly: G: 100x100x3
-
Use gradient descent to minimise :
Content Cost function
- Pick a layer l (can experiment with the various layers).
- Use pretrained ConvNet (eg VGG).
-
Calculate the difference between the activations on the generated image and the source using an element wise sum of square of differences:
.
Style Cost function
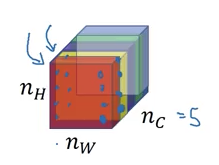
- Take a single activation from a layer l and, for each channel, calculate the correlation between activations.
-
For each position in a channel, how different is each value.
-
What does it mean for two activation to be correlated?
- Example: when a certain texture occurs, a tone or colour also occurs.
- Style matrix:
- let
- is (square matrix)
- - measures how correlated activation in are to .
- K ranges from 1 to .
- Compute the same thing for the generated image, then calculate the different to get the style cost.
- May also use a normalisation constant:
1 / (2 * n_H * n_W * n_C) - Style cost function:
- Sum the style function over all different layers, using a weighting for each layer.
1D and 3D generalizations
- Convolutions in 2D
- Take a 14x14 2D input image and convolve with a 5x5 2D filter results in 10x10 (with stride 1).
- Number of channels in input, matches convolved output.
- Convolutions in 1D
- EKG machine output an example.
- Apply a 5x1 filter at various positions.
- End up with 10x1 output.
- Convolutions in 3D
- Cat scans, movie data etc.
- 14x14x14x1 * 5x5x5x1 = 10x10x10x1.