Imagen 4 is faster, but GPT is still the GOAT
Yesterday, Google announced a bunch of new generative tools at the ongoing Google I/O event. Although, at the time of writing, they're mostly unavailable outside of the USA:
- Veo 3: state-of-the-art video generation that can generate videos with audio.
- Veo 2: updated to include camera controls, outpainting, and adding and removing objects.)
- Flow AI: a filmmaking tool that appears to be used to create videos with continuity between clips.
- SynthID Detector: a tool for detecting the SynthID watermark that Google inject in all generated content.
- Lyria 2: an updated version of the music generation tool.
- Imagen 4: This promises a number of improvements to Imagen 3, including supporting up to 2k resolution and improved typography.
Imagen 4 seems to be the only thing available to me right now in Australia, and only via the Gemini app. However, when generating images in Gemini, they don't mention the model name in the image outputs - I'm not sure if I'm testing Imagen 3 or 4. Imagen 4 is publicly available on Fal.ai; however, as a preview, I'm not sure I quite understand the logic behind that, but I do appreciate how complicated shipping products at Google's scale is.
I did a quick test of some prompts to compare Imagen 4 to OpenAI's gpt-image-1, which is currently the SOTA for image gen.
TL;DR gpt-image-1 is still the greatest for overall quality and prompt adherence, but Imagen 4 is about 5- 10x faster. They are both incredible image generators.
"A group of Mercians, from the Kingdom of Essex in the year 500, sit around a table showing each other a picture on an iPhone."
| Imagen 4 | gpt-image-1 |
|---|---|
 Gen time: 10.21s |
 Gen time: 62.00s |
In terms of aesthetic quality and prompt adherence, gpt-image-1 is the clear winner. The phone is turned around the wrong way in the Imagen 4 version, and it feels more AI-slop-esque. However, you can see that Imagen 4 ran about 6x faster.
"A group of young women, in the 1920s, watch as one of them flies a drone in the streets of Brooklyn, NYC."
| Imagen 4 | gpt-image-1 |
|---|---|
 Gen time: 9.6s |
 Gen time: 47.25s |
In this example, I would say this is one rare example of Imagen 4 being better, although both are really good.
"Leonardo da Vinci sits at a HP laptop, prompting ChatGPT with the text: 'portrait of a woman with a mysterious smile, folded hands, and a soft, mountainous background', the Mona Lisa is shown on screen."
| Imagen 4 | gpt-image-1 |
|---|---|
 Gen time: 8.00s |
 Gen time: 58.70s |
Again, while both are incredible, gpt-image-1 is nearly flawless. The text is a tiny bit off, but overall, it captured exactly the intention, and looks pretty amazing. Imagen 4 leans more towards the AI-slop aesthetic, reminiscent of earlier versions of DALL-E.
I saw a nice paper last year that did some investigation into the poor performance of rare "concepts" in AI image datasets (No 'Zero-Shot' Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance).
The thesis is that image classification and generation models perform much worse on rare concepts in the dataset. They created a dataset of rare concepts (at least rare in the LAION family of datasets) called Let It Wag. I made images with three rare concepts from the Let It Wag dataset: red-necked grebe, Globeflower and SR-20. Not sure how rare these are in OpenAI's or Google's dataset, but it gives some indication of how "rareness" affects the image outputs.
"A Red-necked Grebe sits next to a Globeflower while an SR-20 aircraft prepares for take off in the distance."
| Imagen 4 | gpt-image-1 |
|---|---|
 Gen time: 8.57s |
 Gen time: 57.13s |
I'm no expert on Globe Flowers, Red-necked Grebes or SR-20s, but while Imagen 4 does a really good job, it seems gpt-image-1 is better. But only marginally. These are really impressive results. Both models can do well on even extremely rare concepts.
For the last test, I tested a very specific prompt containing some complicated poses.
I enlisted GPT-4o's help to write this prompt:
A three-frame sequence showing Egyptian queen Cleopatra performing a Romanian deadlift using dumbbells with perfect form: Frame 1 — standing tall at the top of the movement, dumbbells at her thighs; Frame 2 — at the bottom position with a flat back and slight knee bend, weights just below the knees; Frame 3 — halfway up on the return, hips driving forward, maintaining strong posture and control. Photo realistic.
| Imagen 4 | gpt-image-1 |
|---|---|
 Image gen: 5.60s |
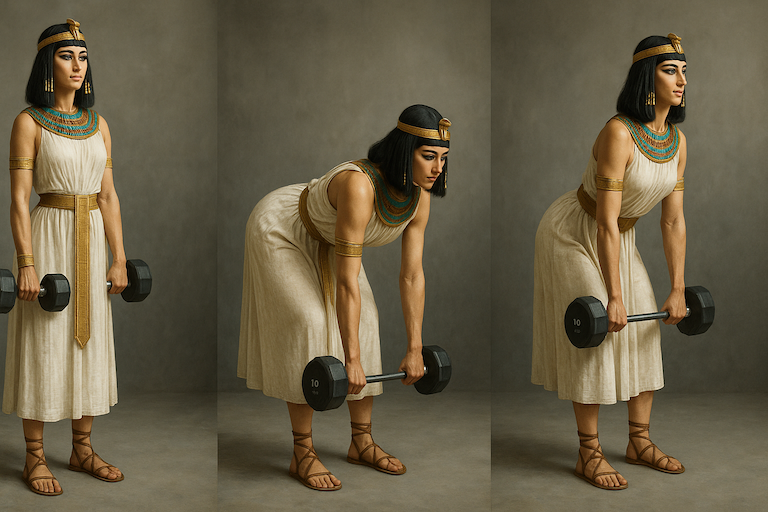 Image gen: 71.47s |
gpt-image-1 got it usefully close. I'd say the form is nearly perfect, although Cleo goes from holding one and a half dumbbells to a barbell. I don't know what exercise Imagen 4 is doing, but it ain't what I had in mind.
Summary
I'd say gpt-image-1 wins in 4/5 of my simplistic tests, based on aesthetics and prompt adherence. However, Imagen 4 was sometimes more than 10x faster than gpt-image-1. I could see Imagen 4 being useful for rapid prototyping and exploration of ideas.