AI Meets the Classroom: When Does ChatGPT Harm Learning?
My notes from the paper AI Meets the Classroom: When Does ChatGPT Harm Learning? by Matthias Lehmann, Philipp B. Cornelius, Fabian J. Sting.
Summary
This paper covers one observational and two experimental studies on the effects of LLM access on students learning to code.
Key findings:
- Using LLMs as personal tutors by asking them for explanations improves topic understanding, though not overall learning outcomes (likely because it reduces the volume of topics covered).
- Asking LLMs to generate solutions impairs understanding. The use of copy-and-paste encourages this behaviour, tripling solution requests without increasing explanation requests.
- Students with stronger prior knowledge benefit more from LLM usage. Students with weaker foundations learned less with AI access.
- LLM access increases students' perceived learning beyond their actual learning outcome, i.e. students think it's a lot more helpful than it is.
In the field study (Study 1), they compare students' work with a number of solutions generated by ChatGPT as a proxy for the use of LLMs. They call this ChatGPT Similarity.
To calculate this, they generate 50 ChatGPT solutions and then take the maximum similarity with a student's code:
for student and question , where is the final student code, is one of the 50 ChatGPT generated solutions, , and is Damerau Levenshtein similarity.
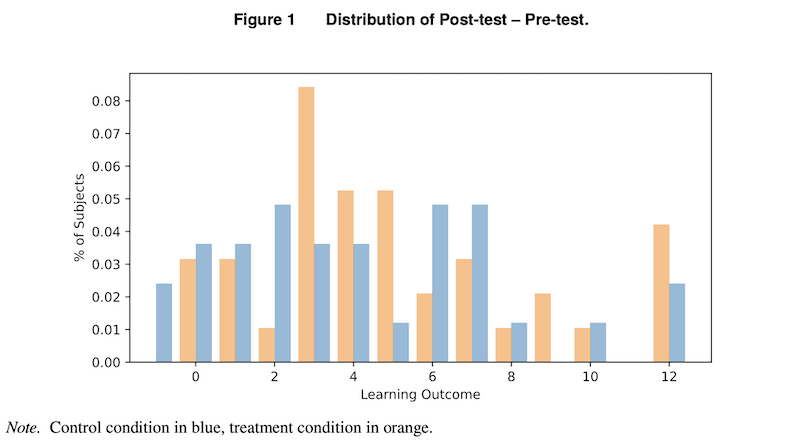
The lab experiments (Studies 2 and 3) instead directly randomised LLM access, comparing treatment (with LLM) and control (without) conditions with pre- and post-tests.