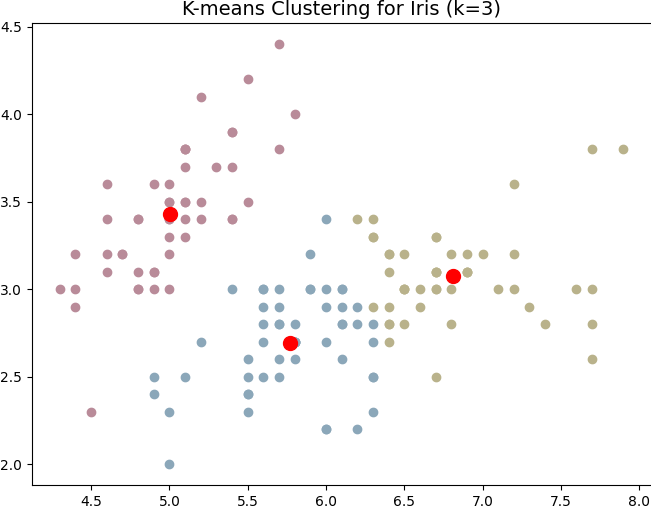
K-Means
K-Means is an unsupervised Clustering algorithm and a method of Vector Quantisation. The goal is to partition data points into clusters, where each data point belongs to the cluster with the closest centroid.
The algorithm works like this:
- Standardise the data by centring at 0 to ensure all features are utilised equally for clustering.
- Randomly create centroids—one for each cluster. Common methods include selecting random data points as centroids or randomly generating centroid coordinates.
- Calculate the distance between each data point and the centroid. Euclidean Distance is commonly used: , where and refer to the feature of datapoint and centroid , respectively. However, other distance functions may be more suitable.
- Assign each datapoint to its closest centroid based on the calculated distances.
- Update the position of the k centroids by taking the mean of all data points assigned to each cluster.
- Repeat steps 4 and 5 until the centroids no longer change or a maximum number of iterations is reached.
The quality of the K-Means clustering is typically evaluated by calculating the average distance of all data points to their assigned centroids. However, K-Means does not guarantee convergence to the global minimum, and the final clustering may depend on the initial centroid positions.