Matrix Determinate
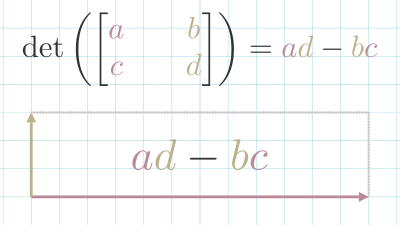
The determinate of a Matrix Transformation refers to how much it scales space.
If we think of the standard Basis Vectors as the sides of a square, we can think of them as having an area of .
Then, if we transform them using matrix , the new area is . So we can say that the matrix has a determinant of 8.
.
Once we know how much a transformation scales a single square, that tells us how any area in space would be scaled, since linear transformations "keep gridlines parallel and evenly spaced." 3Blue1Brown (2016)
A determinate can be a fractional value, which reduces the size of space:
A determinate can even have a negative value, which means that the orientation of space is flipped.
A Matrix Transformation was a determinate of 0, means that the transformation collapses space onto a single line. These types of matrices do not have a Matrix Inverse In 2d space, the Determinate can be calculated using this formula: .
The intuition for this comes when you set and . In that case, the x and y-axis are scaled in a straight line. If you set either or to 0, the shape becomes a parallelogram. But the area is unchanged.
In 3d space, it becomes a lot more complex. We take the product of each element of the first row with the matrix that can be created excluding the current element's column and row.
References
David Dye, Sam Cooper, and Freddie Page. Mathematics for Machine Learning: Linear Algebra - Home. 2018. URL: https://www.coursera.org/learn/linear-algebra-machine-learning/home/welcome. ↩
3Blue1Brown. The determinant. August 2016. URL: https://www.youtube.com/watch?v=Ip3X9LOh2dk. ↩
Khan Academy Labs. 3 x 3 determinant. November 2009. URL: https://www.youtube.com/watch?v=0c7dt2SQfLw. ↩