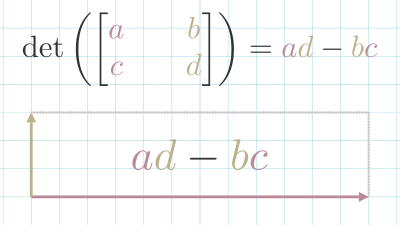The determinate of a Matrix Transformation refers to how much it scales space.
If we think of the standard Basis Vectors as the sides of a square, we can think of them as having an area of 1×1=1.
Then, if we transform them using matrix [2004], the new area is 2×4=8. So we can say that the matrix has a determinant of 8.
det([2004])=8.
Once we know how much a transformation scales a single square, that tells us how any area in space would be scaled, since linear transformations "keep gridlines parallel and evenly spaced." (3Blue1Brown, 2016)
A determinate can be a fractional value, which reduces the size of space:
det([0.50.50.50.5])=0.5
A determinate can even have a negative value, which means that the orientation of space is flipped.
det([−100−1])=−1
A Matrix Transformation was a determinate of 0, means that the transformation collapses space onto a single line. These types of matrices do not have a Matrix Inverse
In 2d space, the Determinate can be calculated using this formula: det([acbd])=ad−bc.
The intuition for this comes when you set b=0 and c=0. In that case, the x and y-axis are scaled in a straight line. If you set either b or c to 0, the shape becomes a parallelogram. But the area is unchanged.
(Dye et al., 2018)
In 3d space, it becomes a lot more complex. We take the product of each element of the first row with the matrix that can be created excluding the current element's column and row.
det⎝⎜⎛⎣⎢⎡a11a21a31a12a22a32a13a23a33⎦⎥⎤⎠⎟⎞=a11 det([a22a32a23a33])−a12 det([a21a31a23a33])+a13 det([a21a31a22a32])
(KhanAcademyLabs, 2009)
References
David Dye, Sam Cooper, and Freddie Page.
Mathematics for Machine Learning: Linear Algebra - Home.
2018. ↩
3Blue1Brown.
The determinant.
August 2016. ↩
Khan Academy Labs.
3 x 3 determinant.
November 2009. ↩