NoProp: Training Neural Networks Without Back-Propagation or Forward-Propagation
an alternative training method to backprop that does local layer learning
an alternative training method to backprop that does local layer learning
a parameter that controls how confident Softmax predictions are
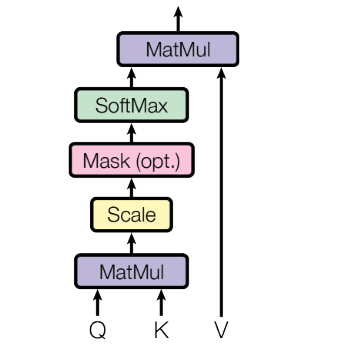
The specific self-attention formulation from the Transformer paper, distinguished by scaling scores by the square root of the attention dimension.
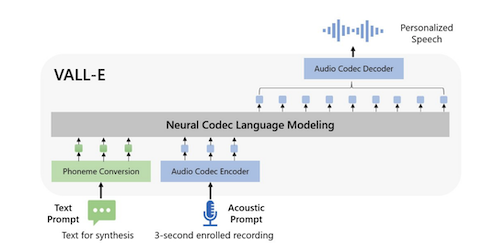
VALL-E can generate speech in anyone's voice with only a 3-second sample of the speaker and some text
A method of computing a token representation that includes the context of surrounding tokens.
the first step to training a neural network successfully

A tokeniser for audio

An activation function for modelling data with periodicity (repeating patterns)

An activation function that outputs a small value for negative numbers
