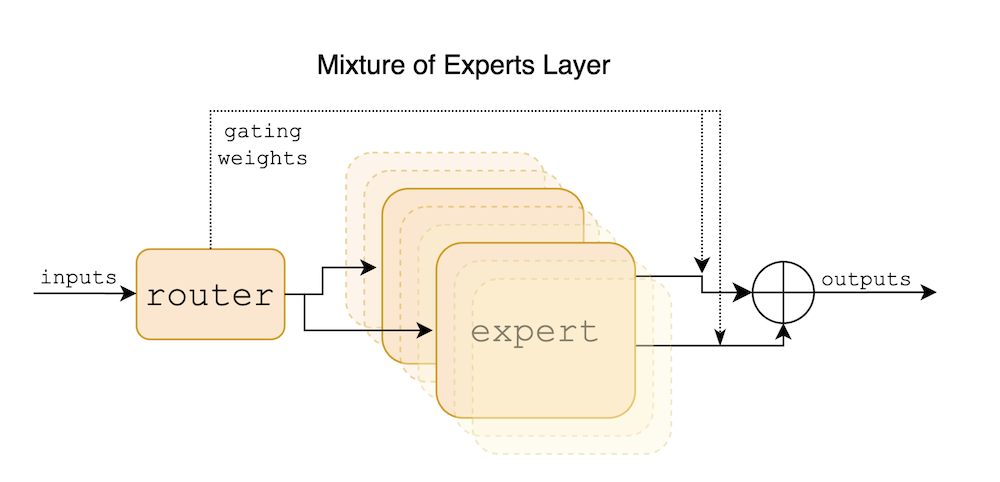
Absolute Zero: Reinforced Self-play Reasoning with Zero Data

learn to reason without any human-annotated data.
learn to reason without any human-annotated data.
a classic paper applying neural networks to RL for game playing

improve zero-shot prompt performance of LLMs by adding “Let’s think step by step” before each answer
improve the Encoder/Decoder alignment with an Attention Mechanism
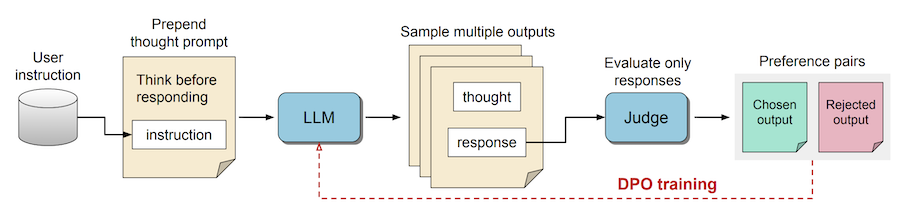
a prompting and fine-tuning method that enables LLMs to engage in a "thinking" process before generating responses
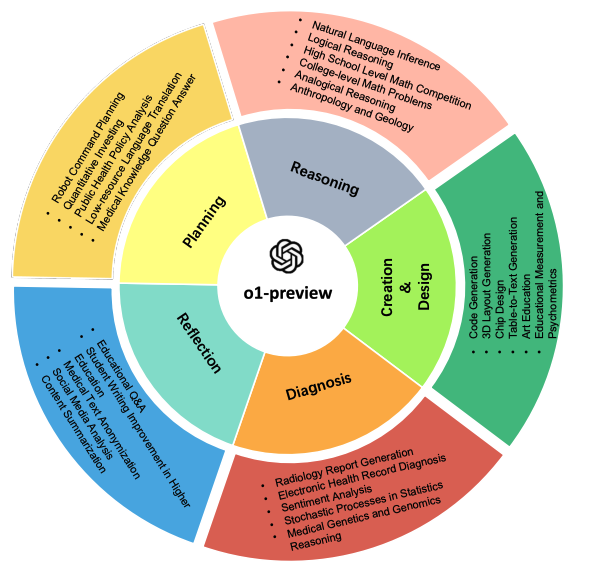
a comprehensive evaluation of o1-preview across many tasks and domains.
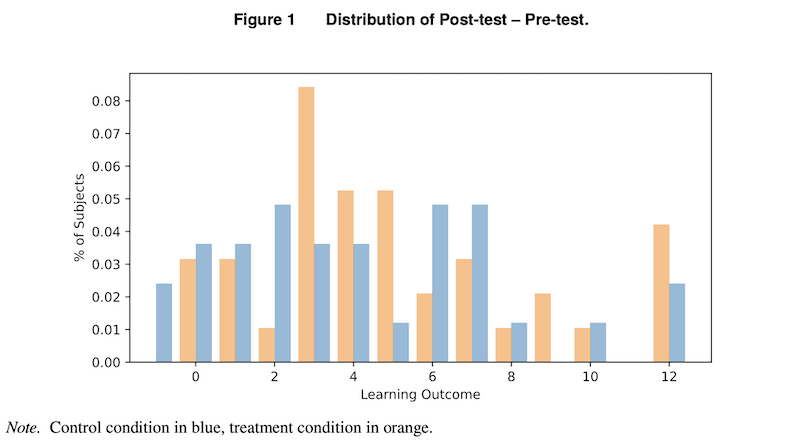
LLMs can help and also hinder learning outcomes
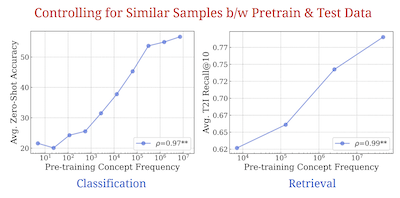
a paper that shows a model needs to see a concept exponentially more times to achieve linear improvements
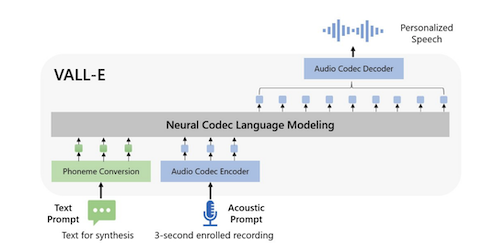
VALL-E can generate speech in anyone's voice with only a 3-second sample of the speaker and some text