LLMs Corrupt Your Documents When You Delegate
Notes on LLMs Corrupt Your Documents When You Delegate by Philippe Laban, Tobias Schnabel and Jennifer Neville.
An interesting paper from researchers at Microsoft.
They introduce a benchmark called DELEGATE-52 that tests whether LLMs can safely carry out, what they call, "long-delegated workflows" for document editing across 52 domains. Every set of instructions in the benchmark is lossless and reversible, allowing the authors to measure how much each task degrades the file's information over multiple interactions.
They found that even the strongest frontier models, including Gemini 3.1 Pro, Claude 4.6 Opus, and GPT 5.4 (the paper was released before their successors), corrupted an average of about 25% of document content after 20 interactions. Across all tested models, average degradation was about 50% (Laban et al., 2026).
Python was the main exception. It was the only domain in which most models met the paper’s “delegation-ready” threshold, with 17 of 19 models scoring at least 98% after 20 interactions.
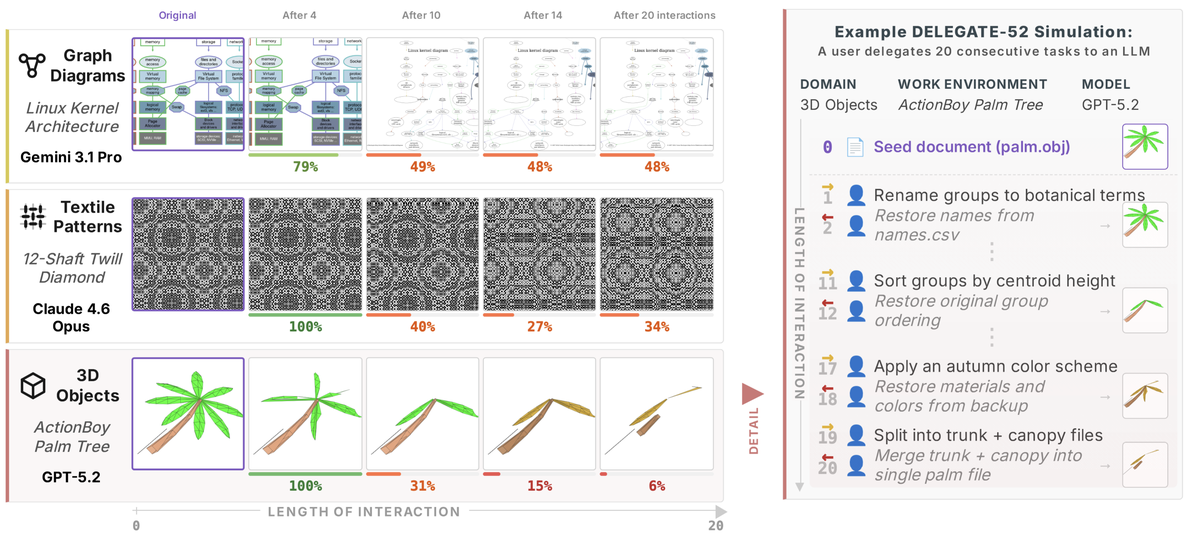
Figure 1 from (Laban et al., 2026) shows examples of document degradation across different domains. The benchmark itself is text-only; the visual renderings are illustrative.
Surprisingly, the degradation didn't happen gradually over instructions, but models would typically fail catastrophically after a certain number of steps. Stronger frontier models would fare better only by delaying the step at which the degradation occurs.
They also found that tool use did not prevent degradation. The tested models performed worse with tools, averaging an additional 6% of degradation.
Measuring Document Corruption
To measure document corruption, they introduce a domain-specific Document Similarity Measure that parses documents into components. For a recipe, that means ingredients (name, quantity, unit), steps, and tips; for Python code, it means functions, classes, and imports. This lets them compare two parsed documents based on their actual content, rather than just raw text. Typical document similarity measures might overlook seemingly small changes, such as 200g to 800g of butter, which can be really bad in a recipe, whereas a surface-level rewrite that preserves the underlying structure doesn't need to be heavily penalised.
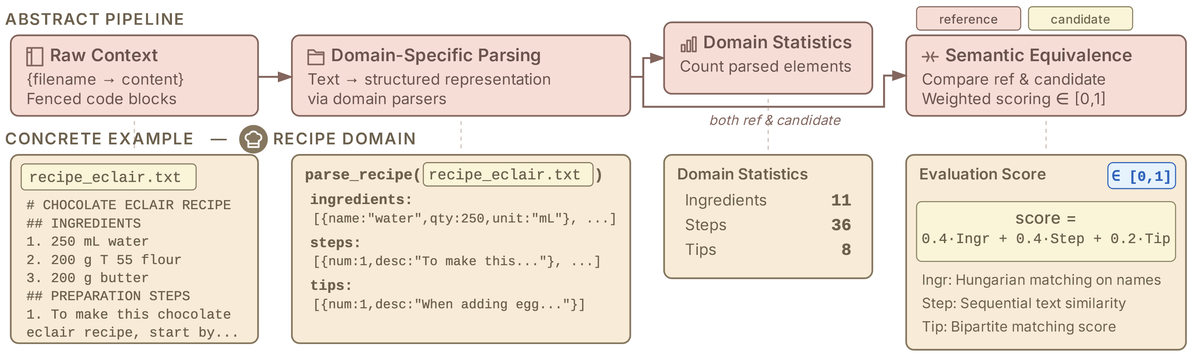
Figure 5 from (Laban et al., 2026) - the domain-specific parsing pipeline, with a concrete recipe example showing how ingredients, steps and tips are extracted and compared
The approach of creating reversible transforms was inspired by Backtranslation, a machine translation technique in which text is translated into another language and then back, allowing the result to be compared with the original. DELEGATE-52 adapts that idea to document editing: apply a forward edit, apply the inverse edit, and compare the reconstructed document to the original. Imagine splitting a CSV into separate files by expense category, then merging them back together. Or converting all amounts in an accounting ledger to euros, then converting back.
They use a round-trip relay simulation method in which every task is assumed to be reversible, defined by a forward instruction and its inverse.
It's worth checking out some examples in the GitHub repo, see music, robotics and Ham radio as examples.
They also tested the inclusion of distractor documents in LLM interactions and found that they harm documents more as interaction length increases.
Basically, degradation severity is exacerbated by document size, interaction length, and the presence of distractor files. However, important to note that the LLM interactions themselves are stateless - it's not just that more noise in context causes outputs to degrade.
The simulation below steps through a recipe domain across 8 round-trips. Each forward edit converts imperial measurements to metric; each backward edit reverts. Watch how errors compound through the document across completely independent calls.
DELEGATE-52
The benchmark contains 310 work environments across 52 domains. Each environment includes real seed documents, distractor files, and 5-10 reversible edit tasks that resemble the kinds of tasks a worker might delegate to an LLM.

Figure 3 from (Laban et al., 2026) - the 52 domains across five categories: Code & Configuration, Science & Engineering, Creative & Media, Structured Records, and Everyday
Figure 4 shows an example work environment from the accounting domain.
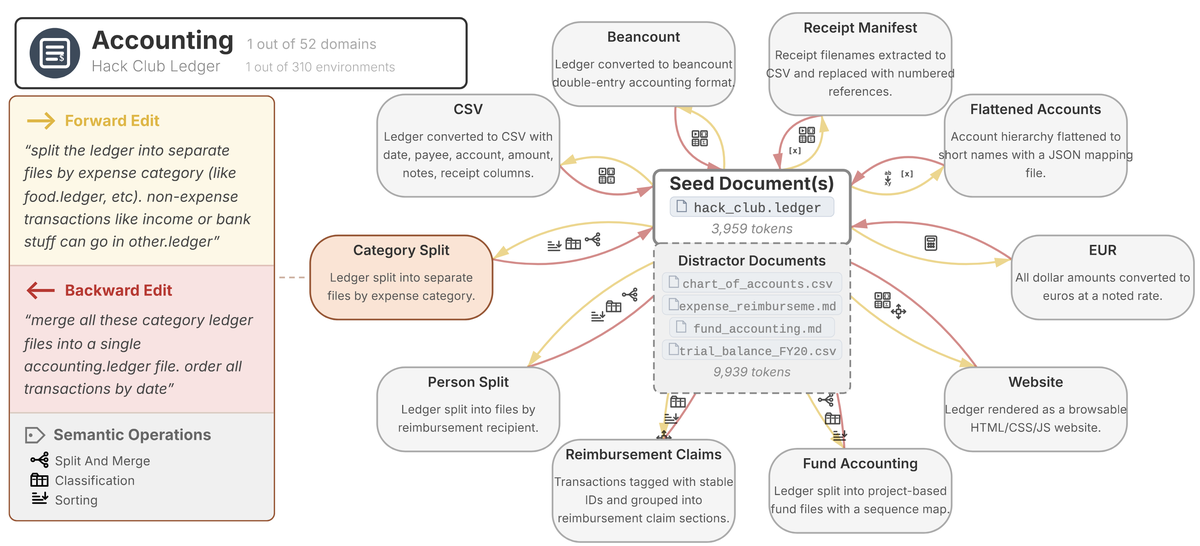
Figure 4 from (Laban et al., 2026) - a work environment from the accounting domain, using a Hack Club ledger as the seed document, with forward/backward edit pairs like splitting by expense category and merging back
Results
They tested 19 models across the benchmark. All 19 models degraded documents over the course of the simulation. The top performers, such as Gemini 3.1 Pro, Claude 4.6 Opus, and GPT 5.4, still corrupted an average of about 25% of the document content after 20 interactions. Across all tested models, average degradation was about 50%, with weaker models failing more severely.
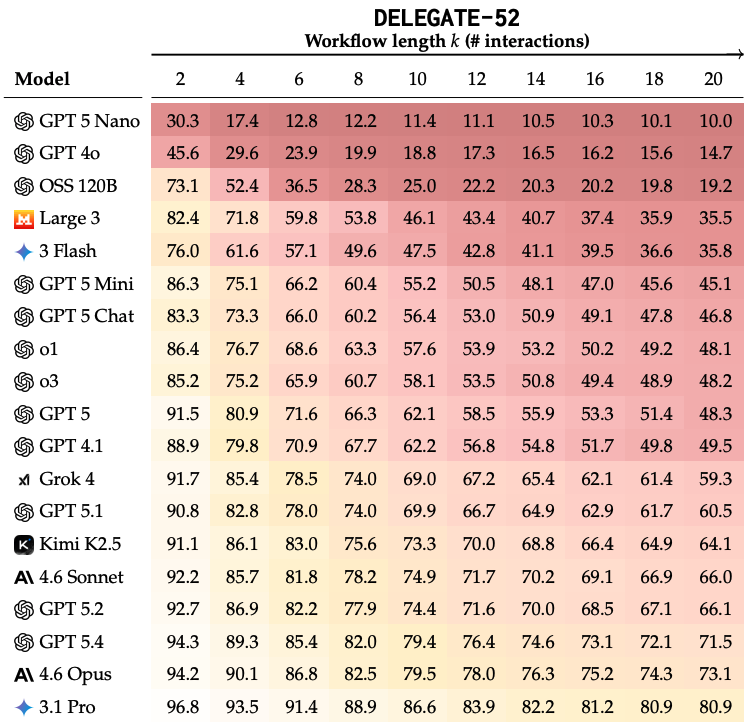
Table 1 from (Laban et al., 2026) - round-trip relay results for 19 LLMs across 20 interactions, colour-coded by degradation severity. Every model declines over time; frontier models delay but do not avoid degradation.
Short-term performance did not reliably predict long-horizon performance. Some models that looked similar after two interactions diverged sharply after twenty, while others that started behind later caught up. This is one of the reasons the paper argues for long-horizon evaluation rather than only testing one-shot or short workflows.
The kind of degradation also changes with model strength. Weaker models tend to lose content through deletion, while frontier models are more likely to preserve content but corrupt it.
Takeaways
One takeaway is that we need to be careful not to extrapolate model capabilities from one area to all domains. Models follow a Jagged Frontier of LLM Capability, where they can excel in some tasks while making serious errors in others. For example, they perform well on Python and poorly on some structured-but-unfamiliar document formats, such as textual 3D object files.
It also raises interesting questions about whether we need to decouple the reasoning engine from the state management system. LLMs may be useful as the reasoning layer, but long-running document workflows probably need external state, parsers, validators, diffs, tests, and reversible operations to prevent silent corruption.
References
Philippe Laban, Tobias Schnabel, and Jennifer Neville. LLMs Corrupt Your Documents When You Delegate. April 2026. arXiv:2604.15597, doi:10.48550/arXiv.2604.15597. ↩ 1 2 3 4 5 6
Video
I've made a YouTube video for this article.
Comments
Reply to this post on Bluesky or Mastodon to join the conversation.