Heavy Thinking: A Test-Time Scaling Pattern for Hard Problems
Notes on HEAVYSKILL: Heavy Thinking as the Inner Skill in Agentic Harness by Jianing Wang, Linsen Guo, Zhengyu Chen, Qi Guo, Hongyu Zang, Wenjie Shi, Haoxiang Ma, Xiangyu Xi, Xiaoyu Li, Wei Wang, Xunliang Cai.
Overview
This paper is an empirical investigation of an Agentic Reasoning approach they call Heavy Thinking (Wang et al., 2026).
It's a simple two-stage workflow: a bunch of subagents reason independently in parallel on a problem, then another LLM "deliberates" over their outputs to generate a final answer.
In Stage 1, the step they call Parallel Reasoning, sub-agents attempt to solve a user query independently, encouraged to approach it from different perspectives, with each outputting both a reasoning trace and an answer.
The outputs are stored in a Serialised Memory Cache, where they are pruned and shuffled. They shuffle the outputs to avoid Position Bias, where the model tends to prefer answers that appear first or last in the context (Bito et al., 2025).
In Stage 2, which they call Sequential Deliberation, the same or another LLM analyses the set of outputs from the previous step and performs meta-analysis to derive a final answer. This can be an iterative process in which the LLM deliberates across multiple steps and optionally includes the deliberation outputs in the parallel reasoning traces at each iteration (they call this Iterative Deliberation).
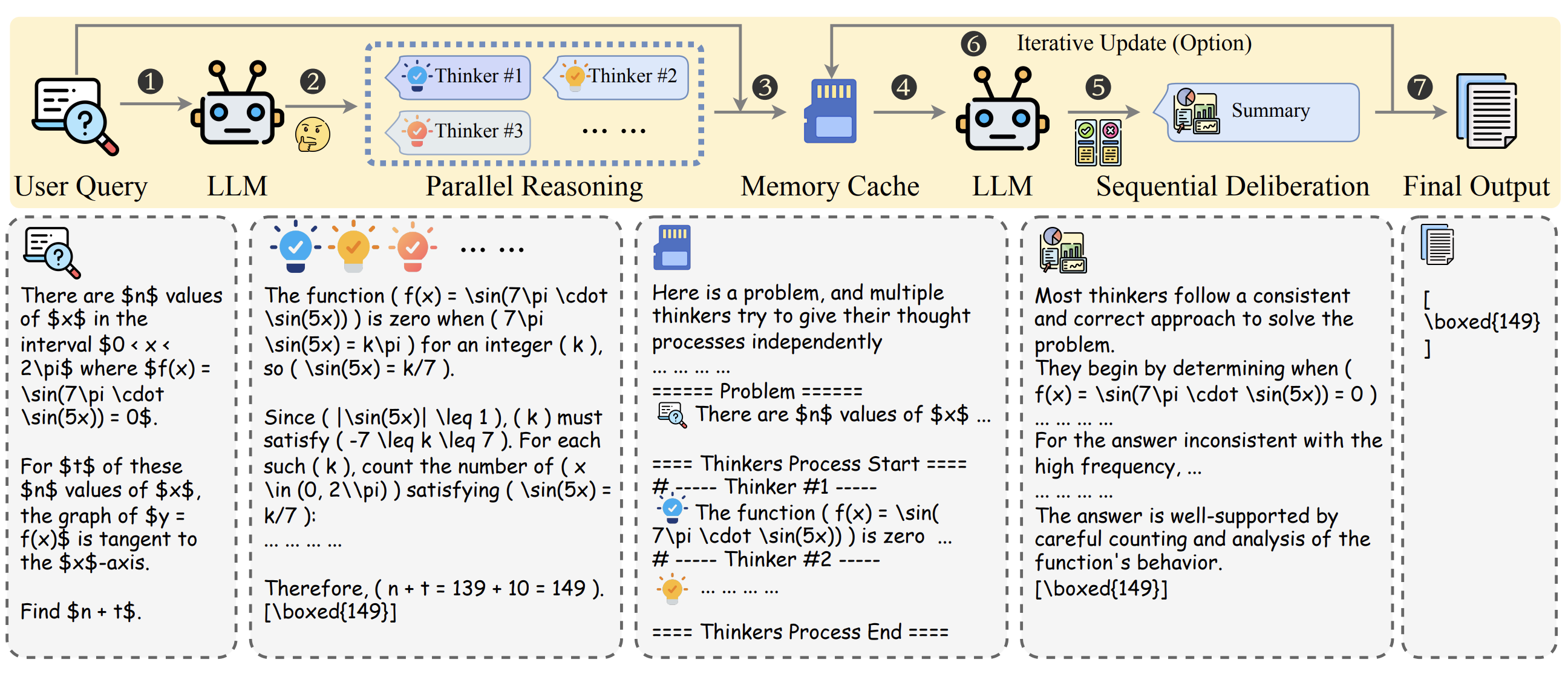
Figure 1. The overview framework of heavy thinking in LLMs test time scaling (Wang et al., 2026).
Since we can scale the number of parallel agents, or the "width" of reasoning, and the number of sequential deliberation steps, the "depth" of reasoning, it serves as a powerful Test-Time Scaling technique.
They argue that the complex orchestration systems behind tools such as Codex, Claude Code, OpenClaw, and Hermes can be abstracted into this two-stage pattern, and are the "inner skill" they use to reason through complex problems.
"We abstract the agentic harness into the LLM’s inherent capability of heavy thinking."
Finally, they propose both a Python pipeline for executing the workflow, and also consolidate the insights into a single Agent Skill called HeavySkill, which can be read in full in the GitHub repo.
We don't know for sure, but others have speculated that GPT‑5.5 Pro uses a similar internal pattern of parallel reasoning chains (Nate, 2025), hence it is about 6x more expensive than GPT‑5.5.
It reminds me a lot of the Stacking ensemble approach in classification-based ML, where a meta-model combines outputs from other models to improve overall performance.
Results
They test both closed-weight (GPT-5 Thinking, Claude 4.5 Thinking and Gemini 3 Pro Preview) and open-weight models (R1-Distill-Qwen-*, Qwen3-*, DeepSeek R1-0528, GPT-OSS-20B, Kimi K2 Thinking, GLM 4.6 and DeepSeek V3.2 Thinking).
By default, the same model is used for both stages, although in theory different models could be used to further improve performance.
On STEM benchmarks, accuracy after deliberation (they call this Heavy-Mean@K) consistently outperforms simply averaging results (Mean@K) across models. In other words, the deliberation step usually improves upon the average single-reasoning trajectory.
Heavy thinking also often beats majority voting (which they call Vote@K). Even when only a few models found the right answer, the deliberation step could reason to the correct answer, despite the majority getting it wrong.
Even more surprisingly, they report that stronger models can approach the upper bound when only one model gets the right answer (Pass@K). In other words, if just one of the parallel attempts found the right answer, a strong deliberation model would identify it.
The strongest results appear on difficult reasoning benchmarks such as AIME25, BeyondAIME, HMMT25-Feb, and GPQA-Diamond. On harder benchmarks, the advantage over voting becomes more pronounced.
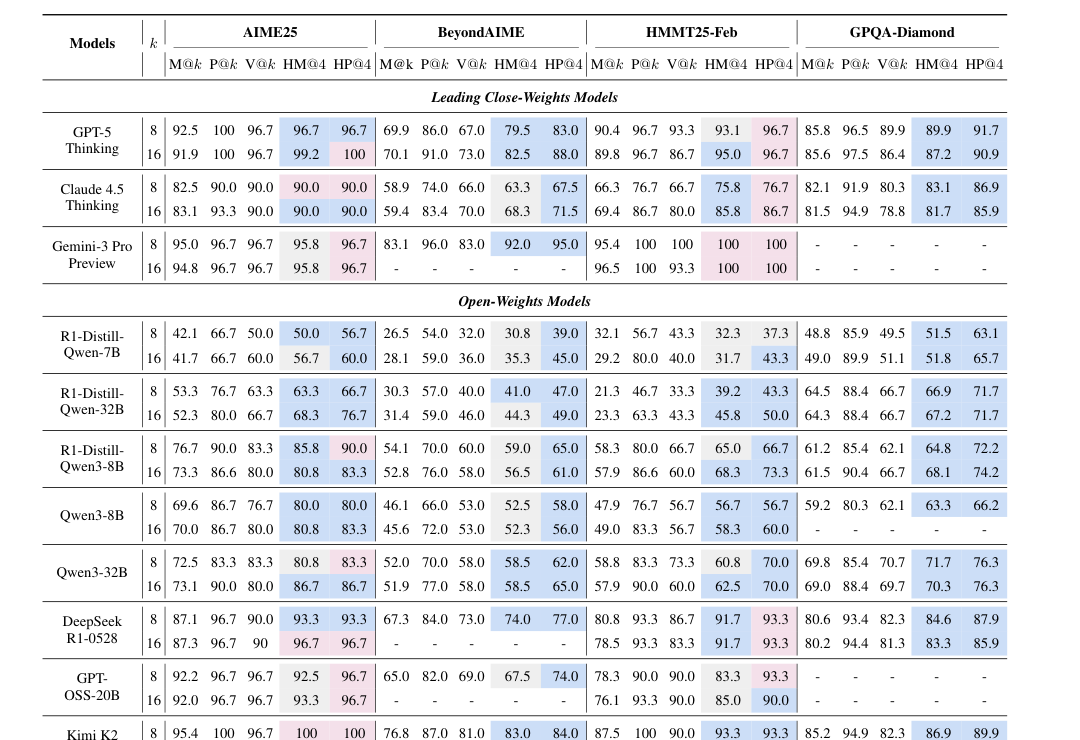
Table 1. Overview performance of heavy mode on STEM tasks (Heavy Mean@4 compared to basic TTS metrics) (Wang et al., 2026).
The results are more mixed outside STEM. Heavy thinking helps on correctness-oriented tasks like LiveCodeBench, IFEval and IMO-style answer benchmarks. These tasks still have relatively clear success criteria. Code either passes tests or it does not. Instruction following can be checked. Math answers can be verified.
But the gains are weaker on Arena-Hard, which is more subjective and preference-based. There may not be a single correct answer. In that setting, combining multiple answers does not necessarily produce something the judge prefers.
Further Analysis
The paper also investigates in depth why heavy thinking works.
Sequential deliberation can rescue low-frequency correct answers
Deliberation can sometimes recover correct answers even when they are not the majority. If 3 out of 16 trajectories are correct, majority voting may still fail. But a deliberation model can inspect the reasoning and decide that the minority answer is actually better.
The authors describe the deliberation model as acting like an implicit verifier. It compares trajectories, identifies inconsistencies, and seeks the strongest reasoning path.
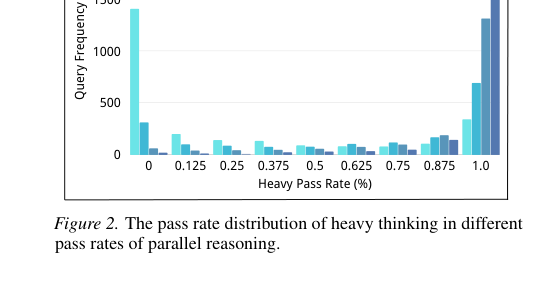
Figure 2. The pass rate distribution of heavy thinking in different pass rates of parallel reasoning (Wang et al., 2026).
The deliberation model does not need to be the best reasoning model
The paper also tests different models in the second-stage deliberation role. The interesting result is that the deliberation model does not necessarily need to be the strongest raw problem solver. It mainly needs to be good at reading reasoning traces, comparing arguments, identifying mistakes and synthesising a final answer.
That suggests the two stages may need different capabilities. The first-stage model needs to generate diverse, high-quality attempts. The second-stage model needs to judge and summarise those attempts well. Again, this feels a lot like meta-models in Stacking solutions, where ensemble diversity tends to matter more than the strength of individual models.
Iteration has a trade-off
Iterative deliberation can improve Heavy-Mean performance as more rounds are added, but it also has a downside: Heavy-Pass can degrade with increasing iterations. The likely reason is that later deliberation rounds can inherit mistakes, noise, or bias from earlier summaries. So, more deliberation is not automatically better.
Heavy thinking also works with tool use
The authors also test heavy thinking in tool-interleaved reasoning scenarios. In these experiments, models can use a Python interpreter during the parallel reasoning stage. Heavy thinking still beats majority voting across the tested models and datasets. This suggests the same pattern works even when the reasoning trajectories include tool feedback.
References
Ethan Bito, Yongli Ren, and Estrid He. Evaluating Position Bias in Large Language Model Recommendations. August 2025. arXiv:2508.02020, doi:10.48550/arXiv.2508.02020. ↩
Nate. GPT-5 Pro: The First AI That's Smarter and Worse at Once. August 2025. ↩
Jianing Wang, Linsen Guo, Zhengyu Chen, Qi Guo, Hongyu Zang, Wenjie Shi, Haoxiang Ma, Xiangyu Xi, Xiaoyu Li, Wei Wang, and Xunliang Cai. HeavySkill: Heavy Thinking as the Inner Skill in Agentic Harness. May 2026. arXiv:2605.02396, doi:10.48550/arXiv.2605.02396. ↩ 1 2 3 4
Comments
Reply to this post on Bluesky or Mastodon to join the conversation.