Optimising Computation At The Token-Level
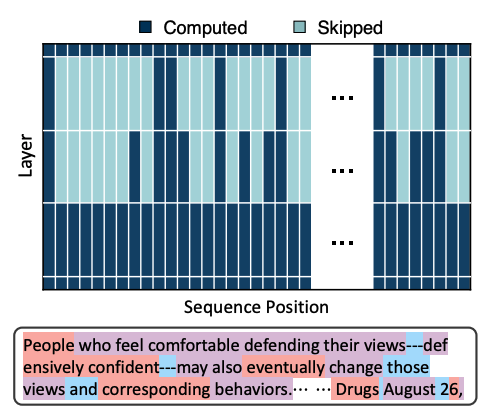
Optimising computation at the token-level
Optimising computation at the token-level
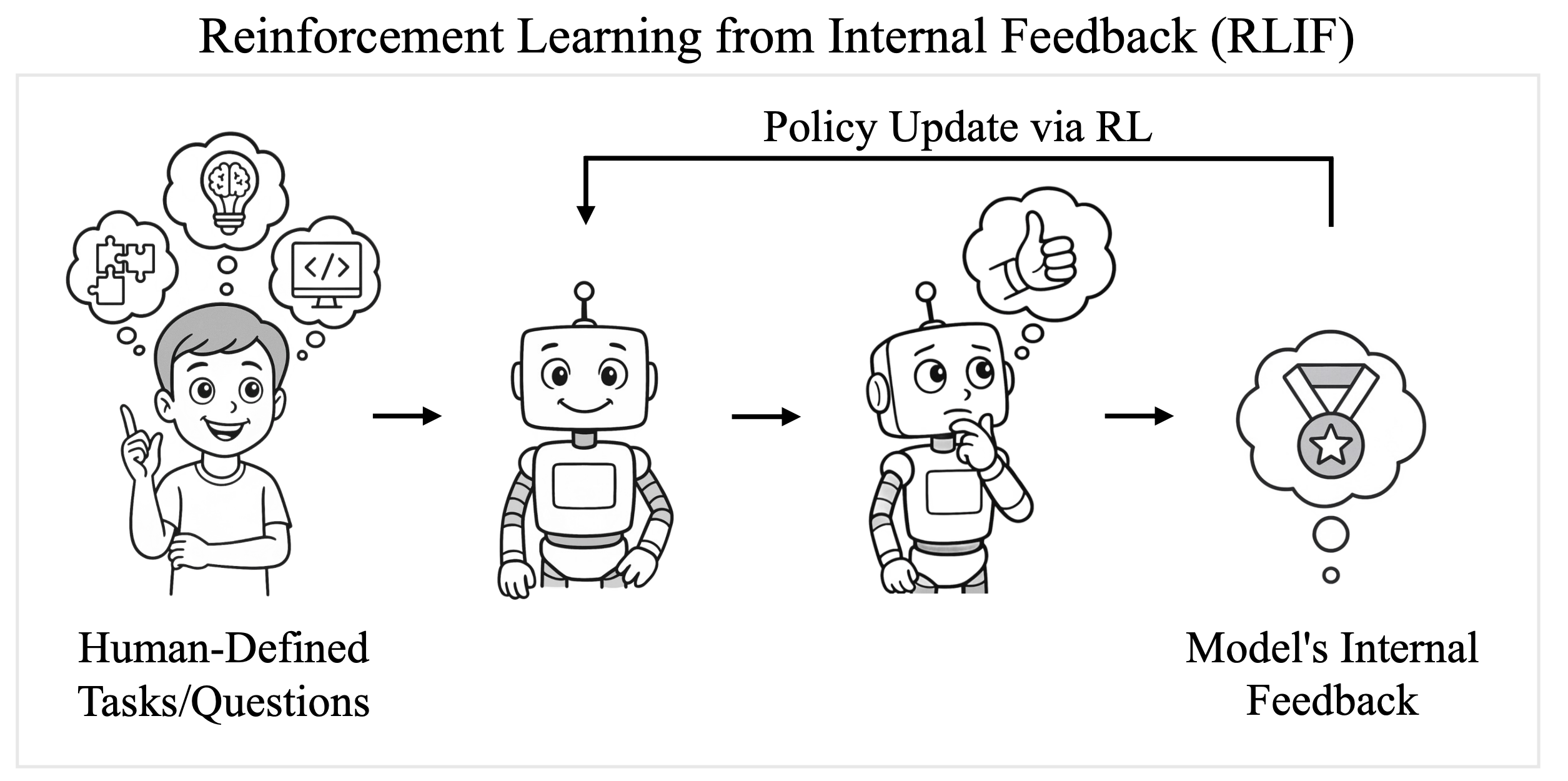
aka Self-Confidence is All You Need
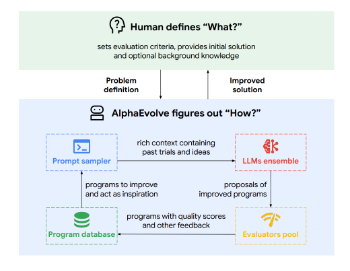
Using evolutionary algorithms with LLM-coding agents
an alternative training method to backprop that does local layer learning

learn to reason without any human-annotated data.
a classic paper applying neural networks to RL for game playing

improve zero-shot prompt performance of LLMs by adding “Let’s think step by step” before each answer
improve the Encoder/Decoder alignment with an Attention Mechanism
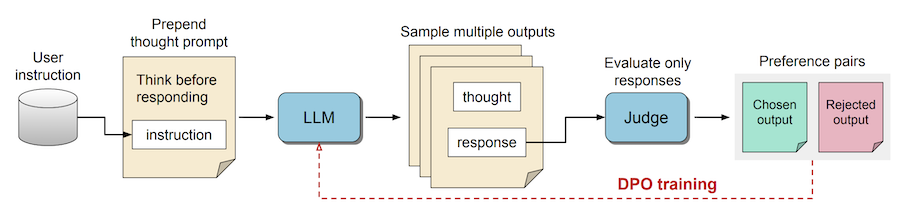
a prompting and fine-tuning method that enables LLMs to engage in a "thinking" process before generating responses
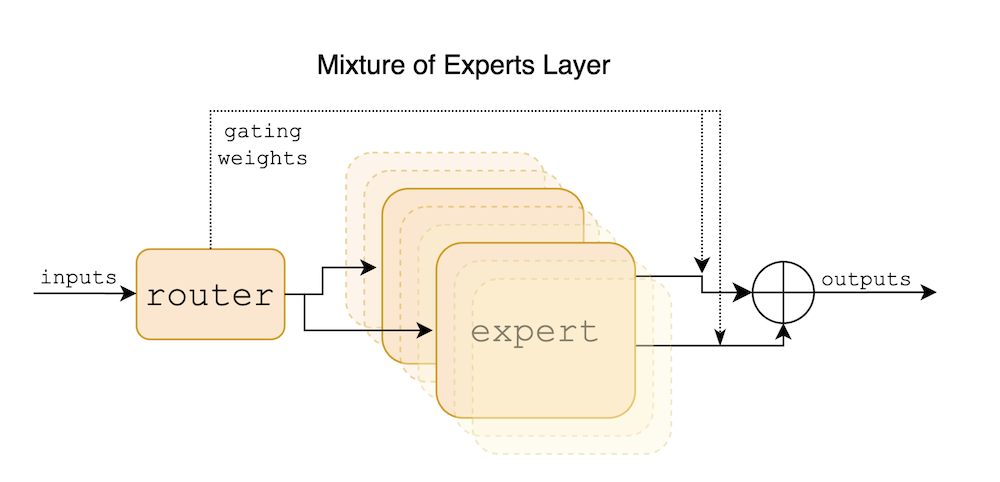
a Sparse Mixture of Experts (SMoE) language model
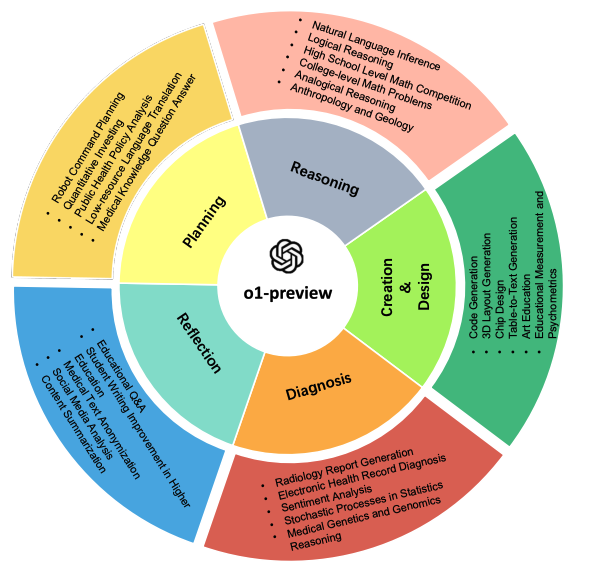
a comprehensive evaluation of o1-preview across many tasks and domains.
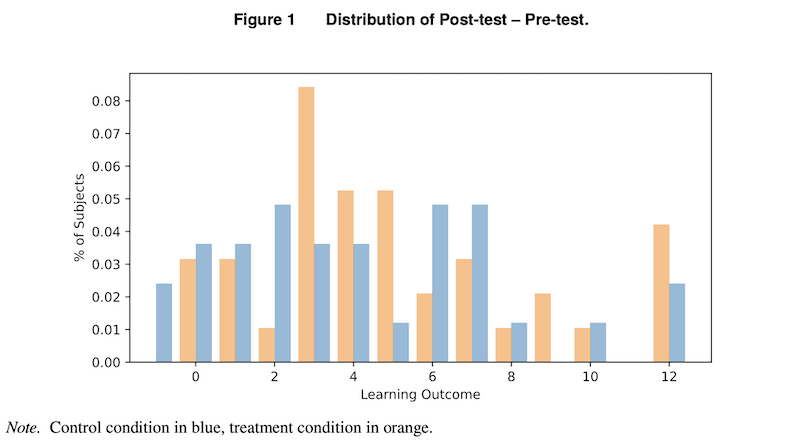
LLMs can help and also hinder learning outcomes
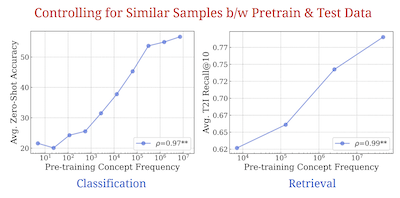
a paper that shows a model needs to see a concept exponentially more times to achieve linear improvements
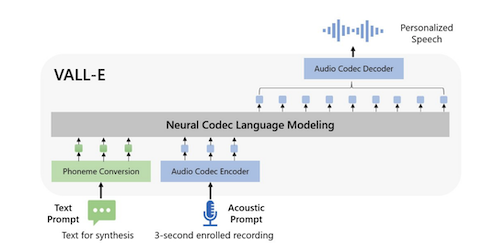
VALL-E can generate speech in anyone's voice with only a 3-second sample of the speaker and some text
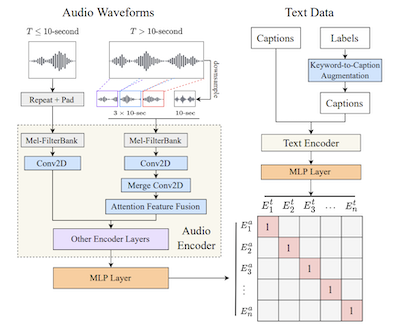
Notes from paper Large-scale Contrastive Language-Audio Pre-training with Feature Fusion and Keyword-to-Caption Augmentation by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov
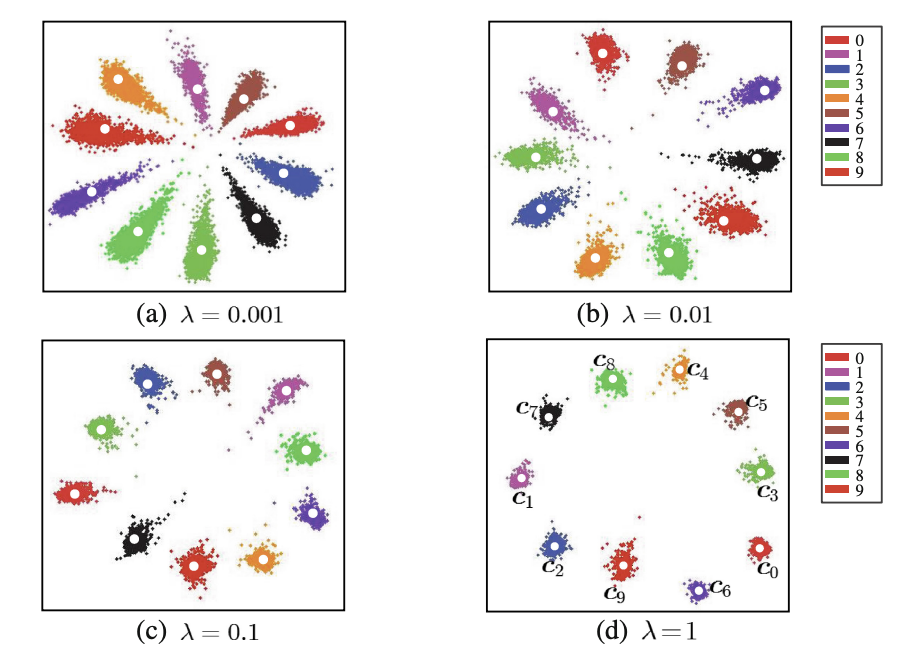
Notes from paper A Discriminative Feature Learning Approach for Deep Face Recognition by Yandong Wen, Kaipeng Zhang, Zhifeng Li, and Yu Qiao
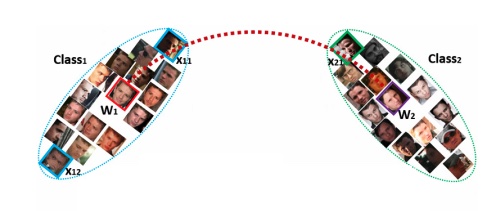
Notes from paper ArcFace: Additive Angular Margin Loss for Deep Face Recognition by Jiankang Deng, Jia Guo, Niannan Xue, Stefanos Zafeiriou