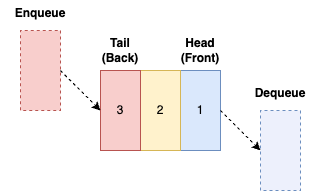
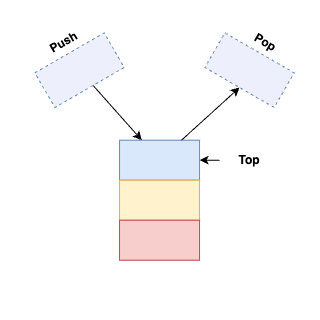
All Notes
-
-
-
Gale-Shapley Algorithm

an algorithm that matches 2-equally sizes groups based on preferences.
-
Merge Sort
a popular divide-and-conquer sorting algorithm
-
Neural Codec Language Models are Zero-Shot Text-to-Speech Synthesizers
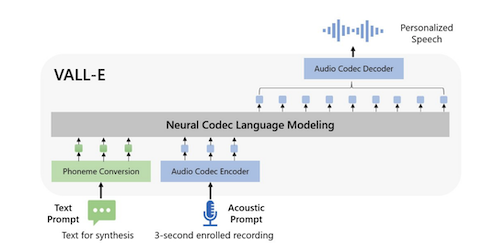
VALL-E can generate speech in anyone's voice with only a 3-second sample of the speaker and some text
-
Self-Attention
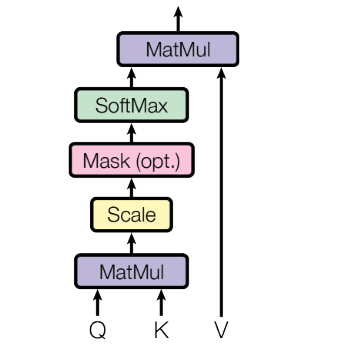
A method of computing a token representation that includes the context of surrounding tokens.
-
Software Development is a Trade

we should educate developers accordingly
-
Convex Hull
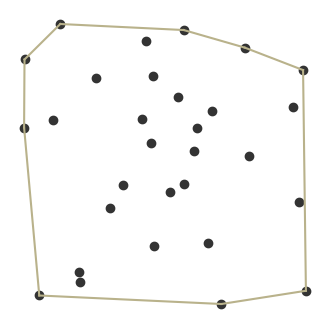
the smallest polygon that contains a set of points
-
Insertion Sort
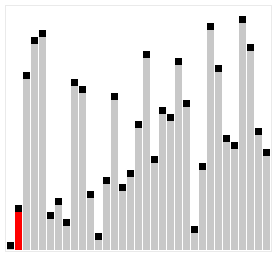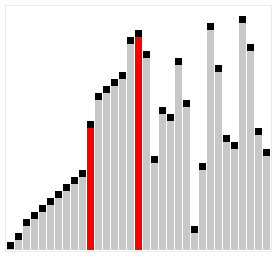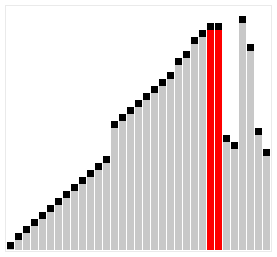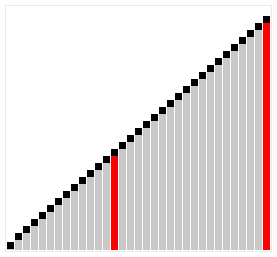
a widely-known iterate sorting algorithm
-
Overfit First
the first step to training a neural network successfully